date: 2024-09-24
title: BDA-Lab-1
status: DONE
author:
- AllenYGY
tags:
- Lab
- Report
- MapReduce
publish: TrueBDA-Lab-1
The problems addressed
Summarize the content of a book 《The Davinci Code》.
Summarize the book from 3 different perspectives:
- Word frequency
- Content Sentiment Analysis
- Content Summary
Approach taken
- MapReduce
- Pretrained Large language model analysis
- Navie Bayes Algorithm
Map the text into several parts
def map(text): #map text to chunks
sentences = sent_tokenize(text)
chunks = []
current_chunk = ""
max_chunk_size = 1000
for sentence in sentences:
if len(current_chunk) + len(sentence) <= max_chunk_size:
current_chunk += sentence + " "
else:
chunks.append(current_chunk.strip())
current_chunk = sentence + " "
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
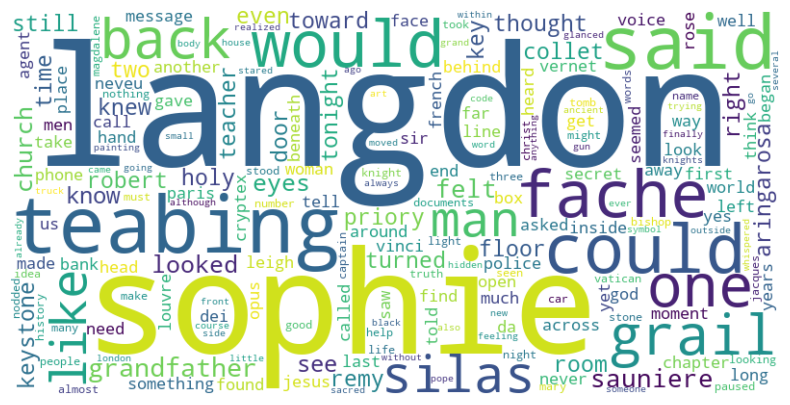
Word Count Analysis
Using NLTK to count the words in the book
- Total Different words : 10873
def word_count(text):
words = [word for word in word_tokenize(text.lower()) if word.isalpha() and word not in stop_words]
freq_dist = FreqDist(words)
return freq_dist
In order to facilitate the presentation of the results, the word cloud map was used to display the results
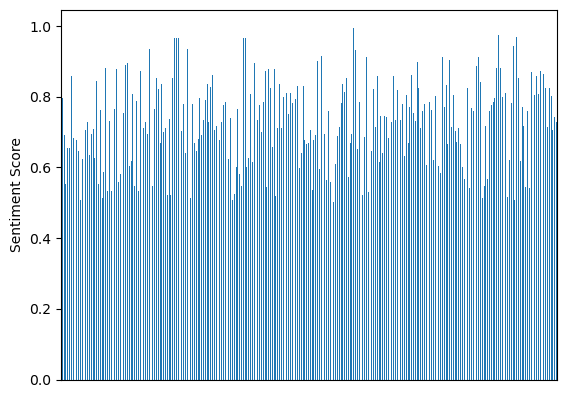
Sentiment Analysis
Divide the book into several parts and use the pretrained model to analyze the sentiment of each part.
Then get an average sentiment of the book.
Average sentiment score: 0.727
def reduce_for_text_sentiment(summaries, index):
# Combine summaries into one text
summary_text = " ".join(summaries)
# Split the combined text into manageable chunks
chunks = map(summary_text)
print(f"Total chunks: {len(chunks)}")
# Initialize the sentiment analysis pipeline
sentiment_analyzer = pipeline("sentiment-analysis", device=device)
# List to hold sentiment results
sentiments = []
# Analyze sentiment for each chunk
for i, chunk in enumerate(chunks):
result = sentiment_analyzer(chunk)
sentiment = result[0] # Extract the first result from the analysis
print(f"Chunk {i} Sentiment: {sentiment}")
sentiments.append(sentiment)
# Save sentiment results to xlsx file
df = pd.DataFrame(sentiments)
df.to_excel(f"sentiments_{index}.xlsx", index=False)
return sentiments
Content Summary
Divide the book into several parts and use the pretrained model to summary each part. (twice)
Pre-trained models summarize the Da Vinci Code
The Da Vinci Code, written by Dan Brown, follows Harvard symbologist Robert Langdon as he becomes entangled in a mysterious murder at the Louvre Museum. Alongside cryptologist Sophie Neveu, Langdon unravels a complex web of codes, symbols, and historical secrets tied to a hidden truth about the Holy Grail and the controversial legacy of Mary Magdalene. The story presents a fictional European secret society, the Priory of Sion, supposedly founded in 1099 and involving famous figures such as Leonardo da Vinci. Another Catholic organization, Opus Dei, emerges in the narrative as a shadowy force, sparking further intrigue.
The plot unfolds through a series of cryptic messages and objects, including a keystone believed to lead to the Grail’s hidden location. Langdon and Sophie encounter numerous obstacles, including Silas, a devout albino monk, and Leigh Teabing, a Grail historian with his own hidden motives. As they decode symbols like the pentacle and the number PHI, they chase leads through significant historical sites like Westminster Abbey and Rosslyn Chapel. The story weaves themes of faith, power, and historical mystery, ultimately suggesting a hidden lineage of Jesus and Mary Magdalene that could challenge traditional Christian beliefs.
def reduce_for_text_summary(summaries,index):
summary_text = " ".join(summaries) # combine the summaries into one text
chunks = map(summary_text)
print(f"Total chunks: {len(chunks)}")
summaries = []
for i,chunk in enumerate(chunks):
inputs = tokenizer(chunk, return_tensors="pt", truncation=True, padding="longest").to(device)
summary_ids = model.generate(inputs["input_ids"], max_length=100, min_length=50, do_sample=False)
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(i)
print(summary)
summaries.append(summary)
save_text(summaries,index)
return summaries
Relevant approaches
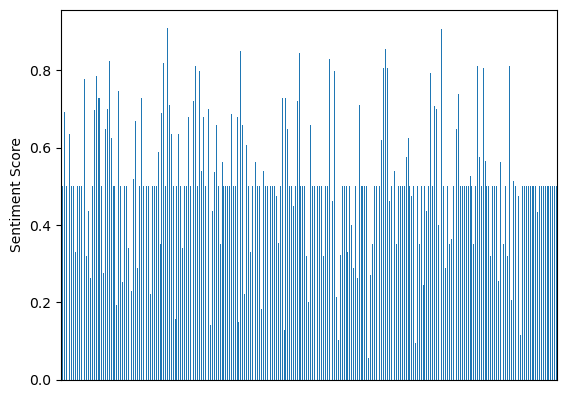
According to the pre-classified sentiment dictionary, classify the text by naive Bayes algorithm
However the result is not as good as the pretrained model.
Average sentiment score: 0.504
This result is almost identical to random score, which means it did not provide a reasonable result.
Evaluation and justification of the approach taken.
-
By using MapReduce to analyze the book, we can get the word frequency, sentiment analysis, and content summary.
-
Compare to the traditional way, this approach is more efficient and can be applied to large-scale data processing.
-
Compare to the navie bayes algorithm, the pretrained model can provide a more accurate and reasonable result.
Data Source Preparation
For the purpose of this project, the digital version of The Da Vinci Code by Dan Brown is available for access and download through this link on the Internet Archive. This novel, a bestseller known for its intricate plot and extensive use of historical and religious references, spans approximately 170,000 words. Given its substantial length and rich content, The Da Vinci Code serves as an excellent resource for detailed literary analysis, sentiment analysis, or natural language processing tasks. The novel’s considerable word count classifies it as a long-form novel, providing ample data for a variety of text-based analyses and studies.