date: 2024-10-27
title: BDA-Lab-2
status: DONE
author:
- AllenYGY
tags:
- Lab
- Report
- PageRank
publish: TrueBDA-Lab-2
1. The problems addressed
Goal: Automatically construct a social network of main characters from the book Harry Potter and the Sorcerer's Stone.
This project seeks to build an automated process for extracting and visualizing the relationships between characters from a novel. By identifying these relationships, I aim to construct a knowledge graph that can reveal social dynamics within the story and highlight the influence of key characters. Additionally, by applying association mining and ranking algorithms, I can identify central figures and their interactions, uncovering character importance based on the narrative context.
1.1. Background
Character networks are a powerful tool for understanding story structure and character interactions within a narrative. By constructing a network from a text, I can better understand the influence and relationships of main characters, as well as visualize social dynamics within a story. In this project, I use machine learning and natural language processing (NLP) methods to achieve this automatically, focusing on entity extraction, relationship detection, and visualization.
1.2. Previous Work
In the previous lab, I used a pretrained BERT model to generate a summary of Harry Potter and the Sorcerer’s Stone, focusing on condensing the storyline to capture essential events and character dynamics. However, I found that understanding relationships within the text requires more than a summary; the text is rich in complex and often implicit relationships between characters. Directly identifying these relationships through rule-based methods or simple keyword matching is challenging due to the intricate, ambiguous, and context-dependent language used in the narrative.
To address these complexities, I chose to use the BERT model again in this lab, this time to identify character relationships. BERT’s ability to grasp nuanced meanings allows us to extract a clearer representation of character interactions. With pretrained language models, I can leverage their deep contextual understanding, bypassing some of the limitations of traditional natural language processing (NLP) techniques.
The aim in this lab is to expand beyond summarization to focus specifically on identifying relationships between characters and building a structured knowledge graph. This graph provides a visual and analytical tool for representing the social network within the story, enhancing our ability to analyze and understand the relational patterns and central characters of Harry Potter and the Sorcerer’s Stone.
1.3. Constructing the Social Network
The social network of characters is represented in two main components:
- Nodes: Represent the characters in the book.
- Edges: Represent the relationships between these characters.
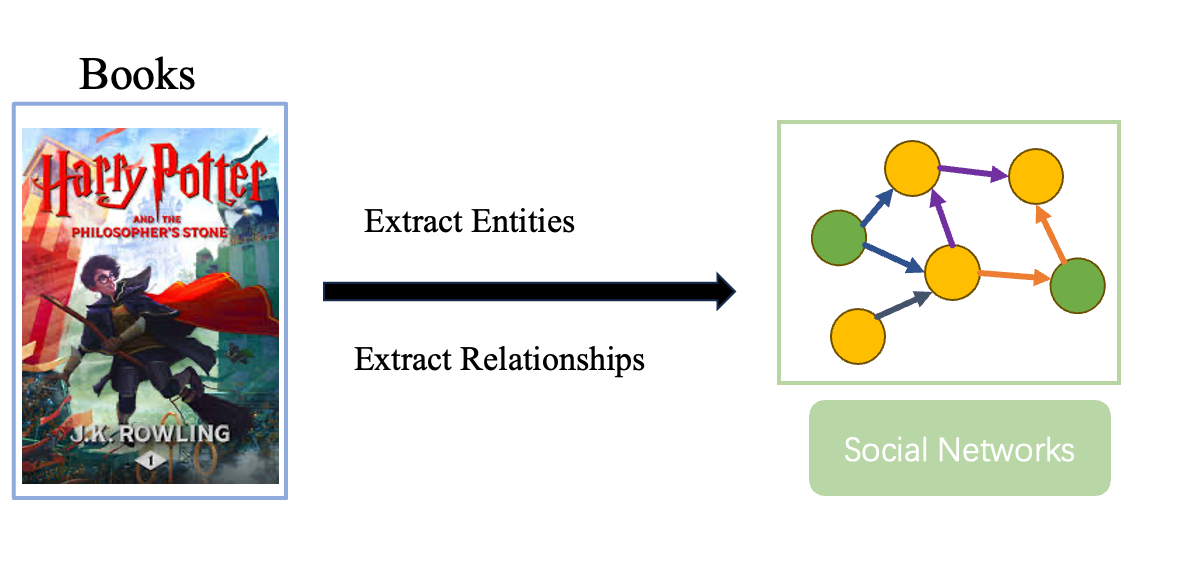
Our approach is organized into three main steps: Entity Extraction, Relationship Extraction, and Knowledge Graph Construction.
1.3.1 Entity Extraction
- We use spaCy to extract named entities, focusing specifically on character names (e.g., Harry Potter, Hermione Granger).
- This involves Named Entity Recognition (NER) to filter and retain only entities labeled as persons.
def extract_entities(text):
words = word_tokenize(text)
pos_tags = pos_tag(words)
chunked = ne_chunk(pos_tags, binary=False)
entities = []
for subtree in chunked:
if isinstance(subtree, Tree) and subtree.label() == "PERSON":
entity = " ".join([leaf[0] for leaf in subtree.leaves()])
entities.append(entity)
return entities
1.3.2. Relationship Extraction
We employ two approaches to extract relationships between entities: spaCy Dependency Parsing and Pretrained BERT Model.
1.3.2.1. spaCy Dependency Parsing
By parsing sentences with spaCy, I identify syntactic dependencies (e.g., subject-verb-object structures) to detect relationships between entities. This allows us to infer direct relationships based on grammatical structure.
def get_entity_relationships(text):
words = word_tokenize(text)
pos_tags = pos_tag(words)
entities = extract_entities(text)
relationships = []
for i in range(len(entities) - 1):
entity1 = entities[i]
entity2 = entities[i + 1]
relation = None
start = words.index(entity1.split()[0]) + len(entity1.split())
end = words.index(entity2.split()[0])
for j in range(start, end):
if pos_tags[j][1].startswith("VB"): # find Vb
relation = pos_tags[j][0]
break
if relation:
relationships.append((entity1, relation, entity2))
#remove duplicate
relationships = list(set(relationships))
return relationships
1.3.2.2. Pretrained BERT Model
Using a BERT-based NER model helps capture nuanced relationships that may not be directly linked through syntax alone, allowing for richer contextual understanding of connections between characters.
1.3.3. Knowledge Graph Construction
- We utilize Neo4j to build and visualize the knowledge graph. Here, characters are represented as nodes, and relationships between them as edges.
- Each edge captures the interaction type (e.g., “friends with,” “enemy of”) based on verbs or action words derived from the text.
def create_relationships(df, graph):
for _, row in df.iterrows():
character_a = Node("Character", label="Character", text=row["Character"])
character_b = Node("Character", label="Character", text=row["Target Character"])
graph.merge(character_a, "Character", "text")
graph.merge(character_b, "Character", "text")
relationship = Relationship(character_a, row["Relationship Type"], character_b, notes=row["Notes"])
graph.create(relationship)
1.4 Social Network Visualization
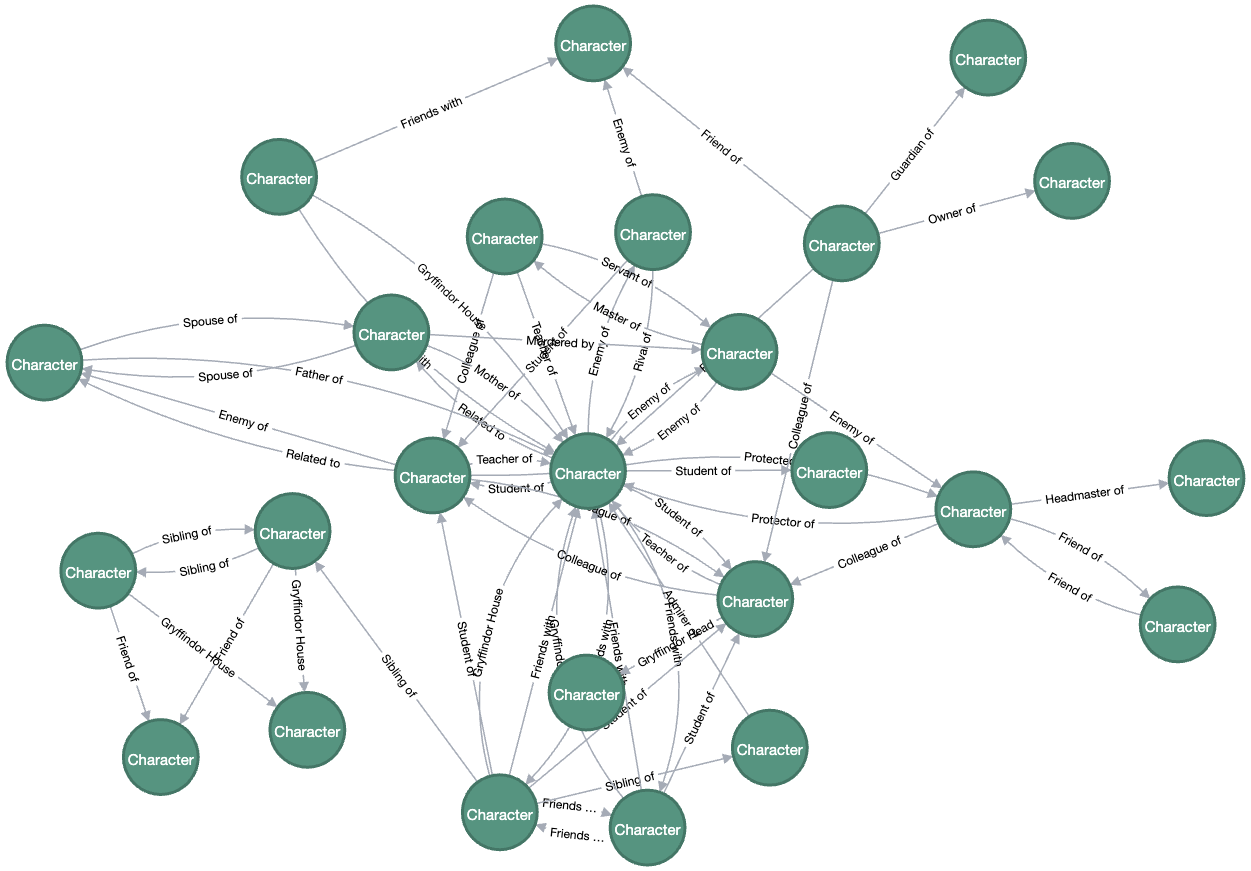
With the Neo4j database, I visualize and explore the relationships in the character network. This allows us to:
- Identify Key Characters: Use centrality measures to find pivotal figures in the network.
- Analyze Relationship Dynamics: Track patterns such as alliances or rivalries by filtering specific relationship types.
1.5. Association Mining
Objective: Identify and rank the main characters based on their significance and centrality in the character network.
PageRank is a powerful tool that I use in this context to rank the characters according to their significance in the story. Here’s a breakdown of how PageRank works and how it helps us analyze the network of characters:
-
Using PageRank to Find Main Characters:
- PageRank Basics: Originally designed to rank web pages by their importance, the PageRank algorithm considers both the quantity and quality of connections to each node (character, in our case) in a graph. A character with many connections, or connections to other well-connected characters, will have a high PageRank score.
- Application to Social Network: By applying PageRank to our knowledge graph of characters, I assign scores that represent each character’s relative importance within the story. Characters with high PageRank scores tend to be those who interact most frequently or with other prominent characters, highlighting them as central figures.
- Main Character Identification: Characters with the highest PageRank scores are likely central to the story, as they either have many direct interactions or connect with other important characters.
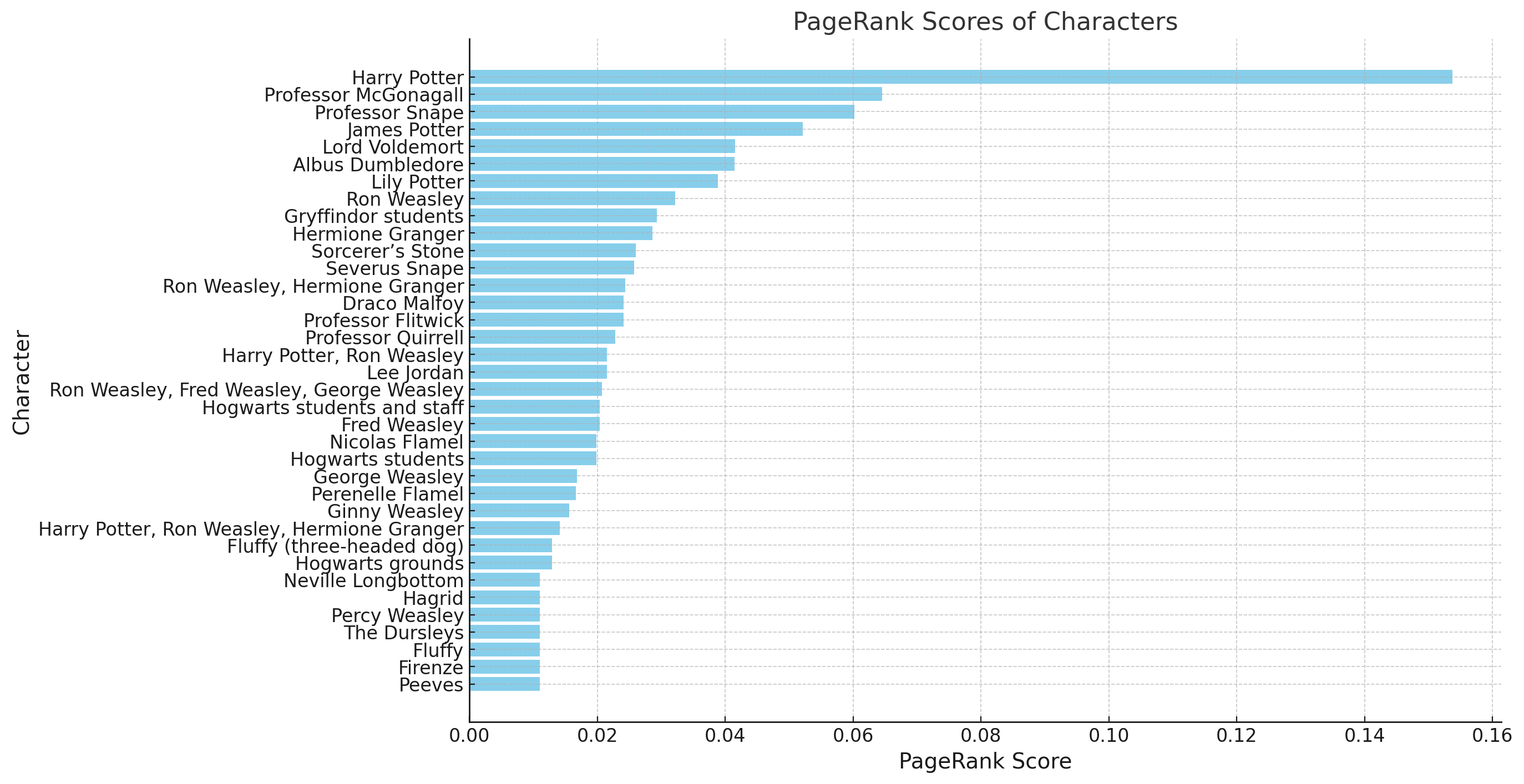
-
Analysis of Results:
- Insight into Social Structure: PageRank doesn’t just count relationships; it evaluates their importance, meaning a character with fewer but stronger or more meaningful relationships may rank higher than a character with many minor connections. This helps in identifying not just the protagonists but other influential characters who play key roles in the story’s dynamics.
- Uncovering Hidden Dynamics: Some characters may appear more central than expected. For example, a minor character with strategic connections to main characters can gain a surprisingly high PageRank score, revealing hidden dynamics or potentially under appreciated roles.
- Visualizing Social Hierarchy: PageRank results provide a clearer picture of the social hierarchy, shedding light on character prominence beyond simple relationship counts and offering a more nuanced understanding of influence and connectivity.
By leveraging PageRank, I achieve a deeper, data-driven understanding of the story’s social network, which complements traditional analysis methods and highlights characters based on their relational significance within the entire network structure. This method is particularly valuable for complex narratives where influence and centrality may not be immediately obvious.
2. Approach Taken
-
Entity and Relationship Extraction:
- To identify characters and their relationships, I used spaCy’s dependency parsing as an initial approach. Dependency parsing provided a way to identify syntactic relations between characters, such as “subject-verb-object” structures, enabling us to detect straightforward relationships.
- Challenges with spaCy: Although fast, spaCy's dependency parsing often missed indirect relationships (e.g., relationships implied through context rather than direct grammatical structure) and subtle associations not explicitly stated in the text.
- To address this, I incorporated a pretrained BERT model for relationship extraction. BERT’s deep understanding of contextual language nuances allowed us to capture both direct and implied relationships by learning from large datasets. This model enhanced our extraction accuracy, especially for complex interactions like alliances, rivalries, and hierarchical relationships within the narrative.
-
Comparison of Methods:
- spaCy:
- Advantages: Fast and efficient for identifying direct, grammatical relationships, making it suitable for quick scans of straightforward sentence structures.
- Limitations: Less effective for nuanced or context-dependent relationships, as it primarily relies on syntactic dependencies rather than context.
- BERT Model:
- Advantages: Strong at capturing complex and implied relationships due to its pretrained nature on a large corpus. It understands context deeply, which allowed us to detect less explicit relationships between characters.
- Limitations: Higher computational requirements, with slower processing times due to the model’s complexity.
- Outcome: By combining both methods, I achieved a balance, leveraging spaCy for speed and BERT for nuanced relationship extraction, improving the overall accuracy of our relationship data.
- spaCy:
-
Graph Construction:
- Neo4j Knowledge Graph: Once entities and relationships were extracted, I built the knowledge graph in Neo4j, where nodes represented characters and edges captured the relationships between them.
- Iterative Graph Population: We incrementally added nodes and relationships based on extracted data. This allowed us to iteratively refine and enrich the graph as more relationships were identified.
- PageRank Computation: To quantify character importance, I used Neo4j’s built-in PageRank algorithm. PageRank is particularly useful in graph-based social networks as it calculates a character’s significance based on the number and quality of their connections. This helped us identify central figures in the story, revealing key characters whose actions influence many others.
3. Relevant Approaches
In our work, I explored three primary approaches for extracting and analyzing character relationships:
-
Direct Text Extraction:
- We first tried simple rule-based methods and keyword matching to directly extract relationships from the text. This involved identifying explicit relationship indicators such as verbs or phrases that linked character pairs.
- Strengths: Quick and effective for simple, unambiguous relationships.
- Limitations: Missed implicit relationships (e.g., relationships inferred through tone or context) and often led to incomplete data due to its rigid nature. Relationships that were context-dependent or complex (e.g., alliances or rivalries that unfold over multiple sentences) were not fully captured.
-
Dependency Parsing and Language Models:
- Dependency Parsing: We used spaCy’s dependency parsing to analyze sentence structure and find relationships based on syntactic dependencies. This approach works well for direct interactions, as it maps grammatical roles within a sentence, such as subject and object, to identify relationship pathways.
- Pretrained Language Models: Using a BERT model, I extracted relationships with greater context sensitivity, capturing implied associations and indirect relationships that are often challenging to detect via dependency parsing alone.
- Strengths: Dependency parsing provides structural clarity for simple relationships, while BERT’s contextual understanding brings out subtler interactions.
- Limitations: Dependency parsing lacks adaptability for context-rich relationships, while BERT, though powerful, requires more computational resources and may need fine-tuning for specific literature-based tasks.
-
Graph-Based Analysis:
- Knowledge Graph Construction: By representing characters and relationships as nodes and edges, respectively, in Neo4j, I could explore relationships visually and structurally.
- Graph Algorithms: Beyond visualizing relationships, I applied algorithms like PageRank to compute the influence or importance of each character within the network. This provided quantitative insights into character significance, identifying central figures who hold key roles in the story's social fabric.
- Strengths: Graph-based analysis, particularly using algorithms like PageRank, allows for an exploration of social structure and character influence, helping us understand the dynamics of the character network.
- Limitations: This approach requires well-extracted relationships to produce meaningful insights, so its effectiveness is tied to the quality of initial data extraction.
4. Data Source
The dataset consists of the full text of Harry Potter and the Sorcerer's Stone. Key considerations in preparing the data included:
- Preprocessing: Text was cleaned and segmented to allow for more accurate entity and relationship extraction.
- Annotation: Entities (characters) were annotated and verified to ensure consistency in the knowledge graph.
- Relationship Validation: Relationships extracted by the model were manually reviewed to ensure accuracy in the final network.
5. Conclusion
In this lab, I explored an automated approach to constructing a social network of characters from Harry Potter and the Sorcerer's Stone by combining advanced entity and relationship extraction techniques with graph-based analysis.
Our process demonstrated the value of using pretrained language models, such as BERT, to capture nuanced relationships within text that traditional rule-based methods may overlook. While spaCy’s dependency parsing provided an efficient initial method for extracting explicit syntactic relationships, the addition of BERT allowed us to recognize more complex associations, enriching the extracted data.
Neo4j served as an ideal platform for storing, visualizing, and analyzing this character network. By constructing a knowledge graph, I could not only visualize the relationships but also apply graph algorithms like PageRank to identify the most influential characters. This quantitative insight complemented the qualitative extraction, revealing central characters who play key roles in the social structure of the story.
5.1. Key Insights and Future Work
-
Insight: Pretrained models capture deeper relationships, though at a computational cost. This approach highlights the trade-off between computational efficiency and the quality of extracted relationships, making it suitable for stories with complex character dynamics.
-
Limitations: While effective, this approach has limitations in handling ambiguous relationships that may require additional context or external knowledge not present in the text.
-
Future Directions: Future work could explore fine-tuning the BERT model for literary text, which may improve extraction accuracy for context-specific relationships. Expanding this approach to other literary texts or genres could also validate its versatility and refine the methods further.
This lab reinforced the power of combining natural language processing and graph analysis for uncovering insights within narrative structures. Such an approach has promising applications not only in literary analysis but also in areas like social network analysis, sentiment analysis, and content recommendation systems.
