date: 2024-11-06
title: Compiler Syntax Analysis
status: DONE
author:
- AllenYGY
tags:
- NOTE
- Compiler
- SyntaxAnalysis
publish: trueCompiler Syntax Analysis
Syntax analysis is the second phase of a compiler.
- Take a stream of tokens from the lexer as input.
- Analyze the structure of the tokens.
- Detect syntax errors.
- Out put a parsing tree to present the structure.
Use context-free grammar (CFG) for analysis.
Context-free grammar (CFG)
- CFG is more powerful than regular expressions.
- CFGs are not the most powerful formal language (see Chomsky hierarchy),
- but CFGs are enough to describe the structures for most of the languages.
CFG
A Context free grammar is a
The production rules are same as the rules in the regular definition.
We can use the rules to derive the strings in a context-free language.
Terminals are the symbols which cannot produce more symbols. In a compiler, they are tokens.
Variables only exists when the production is unfinished.
They are not symbols in the alphabet, neither tokens. Thus, they are not in the strings of the language.
CFG example
For example,
The production rules can also be "combined" and rewritten as
The symbol "|" is same as it is in regular expressions, meaning that there are multiple options.
The rules can be combined only if the LHS are the same.
Sometimes the set of production rules is enough to define a grammar because
- Variables can be obtained by looking at the LHS of each production rule,
- Terminals are the symbols on the RHS of the rules excluding the variables, and
- The start symbol is usually denoted by
Then, the above grammar can be
Derivations
Given a grammar
A derivation (informally) is a procedure to apply the production rules from the start symbol to a string which only contains terminals.
Each production is denoted by
For example, given the grammar
left-most derivation, meaning that each iteration we replace the left most nonterminal.
| Derivation | Rule Used |
|---|---|
| Start symbol | |
| Rule 1 | |
| Rule 5 | |
| Rule 2 | |
| Rule 5 | |
| Rule 5 |
Similarly, the right-most derivation replaces the right most nonterminal in each iteration.
| Derivation | Rule Used |
|---|---|
| Start symbol | |
| Rule 1 | |
| Rule 2 | |
| Rule 5 | |
| Rule 5 | |
| Rule 5 |
Each sequence of nonterminals and tokens that we derive at each step is called a sentential form.
-
The last sentential form only contains tokens and is called a sentence, which is a syntactically correct string in the programming language.
-
If
-
-
From the above example,
Ambiguous
The grammar
- Each derivation (left-most, right-most, or otherwise) corresponds to exactly one parse tree, whether the grammar is ambiguous or not.
- 每个推导(无论是最左推导、最右推导或其他推导)对应唯一一个语法树,无论语法是否有歧义。
- Each parse tree corresponds to multiple derivations, whether the grammar is ambiguous or not.
每个语法树可以对应多个推导,无论语法是否有歧义。 - Each parse tree corresponds to exactly one left-most derivation and exactly one right-most derivation, whether the grammar is ambiguous or not.
每个语法树对应唯一的最左推导和最右推导。 - All derivations of the same sentence correspond to the same parse tree if the grammar is not ambiguous.
如果语法没有歧义,同一语句的所有推导对应相同的语法树。 - Multiple derivations of the same sentence may not correspond to the same parse tree if the grammar is ambiguous.
如果语法没有歧义,同一语句的所有推导对应相同的语法树。 - In general, deciding a grammar is ambiguous or not is undecidable, or uncomputable (like the halting problem).
- 一般来说,判断一个语法是否有歧义是不可判定或不可计算的。
Ambiguity Elimination
A compiler cannot use an ambiguous grammar because each input program must be parsed to a unique parse tree to show the structure.
To remove ambiguity in a grammar, we can transform it by hand into an unambiguous grammar.
This method is possible in theory but not widely used in practical because of the difficulty.
Most compilers use additional information to avoid ambiguity.
CFG VS Regular expressions
| Feature | Context-Free Grammar |
Regular Expression |
|---|---|---|
| Expressive Power | Can handle nested/recursive structures | Cannot handle nested structures |
| Grammar Structure | Production rules with non-terminals | Concatenation, union, Kleene star |
| Applications | Programming language syntax, parsing | Lexical analysis, simple text matching |
| Recognizer | Pushdown Automaton (PDA) | Finite Automaton (DFA/NFA) |
| Example Language | Balanced parentheses | Simple keywords, identifiers |
Limit of CFG
-
To prove a language is not context-free, you need pumping lemma for context free languages.
-
To powerup the CFG/PDA, we can try again to add another stack to the machine, same as what we did to finite automata.
-
This upgrade is ultimate. A finite automata with two stacks is as powerful as a Turing machine, which is the most powerful computational model that human can implement right now.
Pushdown AutomataPushdown Automata
Intuitively, a PDA is a finite automata plus a stack with some modifications on the transitions to fit stack behaviors.
- An NPDA is (formally) a 6-tuple
For example, the context-free language
Top-Down Parsing
Parser
-
Now, we want to implement a parser which
- takes a sequence of tokens as input;
- analyze the structure of the input;
- generates a parse tree; and
- indicates the syntax errors if there is any.
-
There are two types of parsers:
- top-down
- bottom-up.
Top-down parsing tries to construct a sequence of tokens from the grammar which is same as the input.
Bottom-up parsing tries to match the input tokens with grammar rules.
Top-down Parsing
Top-down parsing is only for a subset of context-free grammars.
-
Top-down parsing means that we generate the parse tree from top to bottom.
-
Remember that the internal vertices in a parse tree are the nonterminals (variables), while the leaves are the terminals (tokens).
-
The parse tree construction depends on the production rules in the grammar.
-
If we want to construct the parse tree from top to bottom, the production rules have to be nicely designed.
Leftmost derivation
The RHS of each production rule always starts from a different terminal.
The parsing on the left branch always finishes before the right branch.
For example, the following grammar parses single variable declarations (if we do not care about types here).
Suppose the input is
The input tokens can be uniquely parsed into
Recursive-Descent Parser
However, our life cannot be that easy in most of cases.
- The previous grammar does not allow multiple variable declarations in one statement.
So, consider this grammar.
and try to parse
We have two different choices for the first derivation.
We cannot decide which production rule can be used for the derivation.
The parser will pick a valid rule randomly.
If the guess is wrong, the parser cannot proceed parsing on some input tokens and it will backtrack.
Actually, you have seen backtracking in other places … Depth First Search.
We can express the parsing by using a DFS tree.
- Each vertex in the tree is a valid sentential form (a stream of terminals and nonterminals). In this example, the stream to the RHS of
- Each edge is defined by applying a production rule.
The minor difference here is that we don’t need to go back to the root (as DFS) when the parsing is finished.
Note that this DFS is different from the parse tree because a vertex presents a sentential form, which is equivalent to a (partial) parse tree.

Each nonterminal
- Iterate on every rule starts with
- Remember to resume the tokens when derivation fails.
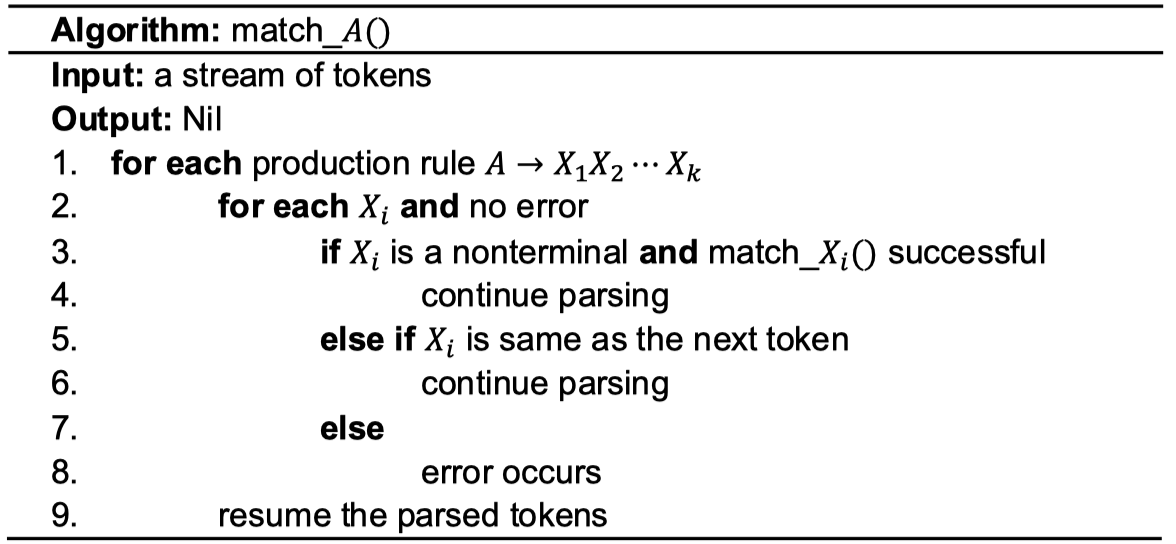
The parse tree generation can be done at Row 4 and Row 6, when the algorithm continues parsing.
You can also record the derivation rules and generate the parse tree when parsing is finished.
Resuming the parsed tokens at Row 9 can be implemented by a stack. When a token is matched with a terminal, push the token into the stack. When error occurs, we pop the tokens and put them back to the input.
The main routine starts from matching the start variable.
The parser reports syntax error when the main routine has tried all possible production rules. A syntax error can be
- the parser receives a token which cannot be parsed;
- after processing all tokens, the parse is incomplete (some leaves are nonterminals); or
- when the parsing is complete (all leaves are terminals), there are some tokens remained in the input.
Disadvantages of Recursive-Descent Parser
- The implementation (in code) can be very complicated/ugly because it needs to try many production rules, imaging many try-catch scopes nested with each other.
- It waste a lot of time on backtracking.
- It needs additional space to store the tokens for resuming purpose.
- In practical, nobody uses recursive descent parser.
Predictive Parser
To avoid backtracking, we want to design a parser which can guess the next token from the input.
A correct guess can let the parser uniquely choose a production rule for parsing.
The idea is using a temporary space to store some tokens in advanced, like a buffer. Then, use the buffered tokens to make decisions.
This technique is very similar to space-time trade-off in the dynamic programming, what we have learned in algorithms.
The time complexity of recursions with backtracking can go up to
But, if we can choose rules uniquely, the time complexity becomes
Consider the grammar
which is equivalent to the above one and try to parse
-
In the first iteration, the parser has to use the rule
-
In the second iteration, there are two production rules "
-
This uncertainty can be easily solved by just “looking” at the next token from the lexer. This token is called lookahead token.
-
Normally, when lexer returns a token to parser, the token is consumed. But the lookahead token remains in the input.
-
The lookahead token in this example is "
Because the parser reads tokens from left to right, does leftmost derivation, and looks at most one lookahead token(could not be a non-terminal); this parser/grammar is called
Some grammars may not be
- For example, the one we have seen.
-
Looking one token ahead is insufficient for this grammar.
-
-
If the lookahead token is “
- This is
- This is
In general, we can design
In practical, more lookahead tokens make no big differences but increase the implementation difficulties.
More importantly,
Left factoring
Left-factoring is a grammar transformation to convert a grammar to
Back to the example,
is not
We can solve this issue by introducing a new nonterminal
And convert the grammar to
The new grammar is
This conversion is called left-factoring.
More formally, for each nonterminal
where
Create a new nonterminal
Left Recursion Elimination
Some grammars are not good enough even after left factoring.
- For example, again to parse the variable declaration
- No production rule has a same prefix on RHS. But lookahead tokens do not work.
Suppose, the parser at some point needs to derive the nonterminal
One may try: if the lookahead token is
If the lookahead token is
Be careful!
As a result,
The problem is cause by
This type of grammar is called left recursive.
Note that this still left-most derivation. Left-most or right-most derivation is not related to grammar itself. It only relates to in which order we derive the nonterminals.
Formally, a left recursive grammar has a valid derivation
where
In general, a left recursive production rule has the form
This production can be derive
The parsing stops at
So, we can let
Note that the production from
But this is not
Formally, for each nonterminal
where
Create a new nonterminal
Exercise
Given the following grammar, try to do left factoring and eliminate left recursions.
Ans:
Limitations
In the last example, the grammar is left associative before conversion, but becomes right associative after conversion.
This totally changes the structure of the parse tree for some expressions, like
“
In fact, top-down parsing cannot solve this issue. We need to either use a bottom-up parser or be stuck into the implementation details.
There are also some unambiguous context-free grammar cannot be converted into
- For example, the one we used to show ambiguity elimination
After left factoring
Here are some last words about (recursive) predictive parsers.
- A predictive parser can always correctly predict what it has to do next.
- Predictive parsers can always be implemented by a recursive parser without using lookahead tokens.
- Without further specification, we consider recursive parsers and predictive parsers are the same.
- One major disadvantages of (recursive) predictive parsers is that they are not very efficient in implementations. Each production rule is implemented as a function. The parser needs to make many function calls and returns, which consume a lot of resources.
To avoid the function calls, we introduce nonrecursive predictive parsers.
Non-recursive Parser
To avoid recursions, we introduce non-recursive predictive parsers.
Intuitively, predictions are required when a nonterminal has multiple production rules.
The predictions are based on the next token. One token is enough because we are parsing
However, this method has troubles when the RHS of some rules start with nonterminals.
- For example
- We cannot decide whether we are going to use
Thus, we can "preprocess" the grammar to find the first tokens derived by each nonterminal before parsing the tokens.
The result of preprocessing is presented by a table, called parsing table.
The rows are the nonterminals and the columns are terminals.
The entry
The parser can parse the input tokens by checking the parsing table and using a stack.
This method is similar to the push-down automata but presented differently.
- Initially, push $ and
Also insert $ to the end of the input stream of tokens.
Parsing using a parsing table
-
In each iteration,
- Assume the next input token is
- Pop the first item from the stack denoted by
- If
- If
- Assume the next input token is
-
When the stack pops $ and all input tokens are consumed, the parsing halts.
-
$ is an artificial token, means the end of the stream.
Example
Given the parsing table and try to parse
| id | + | * | ( | ) | $ | |
|---|---|---|---|---|---|---|
| E | E → TE′ | E → TE′ | ||||
| E′ | E′ → +TE′ | E′ → ε | E′ → ε | |||
| T | T → FT′ | T → FT′ | ||||
| T′ | T′ → ε | T′ → *FT′ | T′ → ε | T′ → ε | ||
| F | F → id | F → (E) |
| Production Rule | Input | Stack | Pop |
|---|---|---|---|
| (id + id) * id $ | $E | ||
| (id + id) * id $ | $E'T | ||
| (id + id) * id $ | $E'T'F | ||
| (id + id) * id $ | $E'T')E( | ||
| Token Matched | id + id) * id $ | $E'T')E | |
| id + id) * id $ | $E'T')E'T | $E | |
| id + id) * id $ | $E'T')E'T'F | $T | |
| id + id) * id $ | $E'T')E'T'id | $F | |
| Token Matched | + id)** * id $ | $E'T')E'T' | |
| + id) * id $ | $E'T')E' | ||
| + id) * id $ | $E'T')E'T+ | ||
| Token Matched | id) * id $ | $E'T')E'T | |
| id ) * id $ | $E'T')E'T'F | ||
| id ) * id $ | $E'T')E'T'id | ||
| Token Matched | ) * id $ | $E'T')E'T' | |
| ) * id $ | $E'T')E' | ||
| ) * id $ | $E'T' | ||
| Token Matched | ) * id $ | $E'T' | |
| * id $ | $E'T'F* | ||
| Token Matched | id $ | $E'T'F | |
| id $ | $E'T'id | ||
| Token Matched | $ | $E'T' | |
| $ | $E'T | ||
| $ | $E | ||
| Token Matched | $ |
Some entries
Meaning that id you try to parse the token
For example, assume the input tokens are
The error handling will be discussed at the end.
Intuitively, a parsing table enumerates all possible tokens can be derived by a nonterminal.
When a parser reads a token from input, it has a unique production rule to apply.
Thus, we need to analyze the grammar and find the prefix (the first token) of all possible sentential form derived by each nonterminal.
First
By putting all the firstly produced tokens into a set, we defined
- For example,
Formally,

Note: each
Follow
When a terminal produces
- For example,
- The parser need to use the rule
However,
To handle this case, we also define
-
In this example,
-
When the parser receives

Parsing Table Construction
Recall the parsing table
The entry
For each production
- For each token
- If
- All other entries in the table are left blank and correspond to a syntax error.
Note that Rule 2 is applied when
To create a parsing table for a non-recursive parser,
- eliminate any ambiguity from the grammar,
- eliminate left recursion from the grammar,
- left factor the grammar,
- compute the
- compute the
- use those
Bottom-Up Parsing
Limit of Top-Down Parsing
Back to the example in Top-Down Parsing. The following grammar is left-recursive.
Thus, top-down parsing needs to eliminate left recursion first.
However, the conversion changes the structure of some sentences, like
Bottom-Up Parsing
Bottom-up parsing is more natural to human.
Think about how we analyze the arithmetic expressions.
First, we calculate the subexpression in parentheses or the operator of the highest precedence.
Then, the intermediate result will involve in the following calculations.
The procedure is not from left to right.
Same thing happens when we analyze sentences in a program.
To the parse tree construction, the bottom-up procedure starts from isolated leaves, merges some of them to form a subtree, and eventually constructs the entire tree by placing a root.
The parse tree generated by bottom-up has no difference with by top-down, the internal vertices are nonterminals and leaves are tokens.
In fact, you have seen the similar procedure in Algorithm – the construction of Huffman code.
Because the bottom-up parsing is an inverse of top-down paring, the basic strategy is to use the LHS of some production rules to replace the RHS after reading some input tokens.
Thus, in the bottom-up parsing, there are two basic operations.
- Shift
- The parser needs to read more tokens from the input.
- The tokens have already read are insufficient for any production rule.
- Reduce
- The parser has already read enough tokens.
- It can replace the RHS by the LHS of some production rules.
The parser is called shift-reduce parser.
The parser also needs a stack to hold the tokens which are read but not consumed (reduced) yet.
Example of Bottom-Up Parsing
- Let’s look at a small example first. Given the following grammar and try to parse
| No. | Stack | Input | Output |
|---|---|---|---|
| 0 | abbcbcde | ||
| 1 | a | bbcbcde | shift |
| 2 | ab | bcbcde | shift |
| 3 | aA | bcbcde | reduce using A → b |
| 4 | aAb | cbcde | shift |
| 5 | aAbc | bcde | shift |
| 6 | aA | bcde | reduce using A → Abc |
| 7 | aAb | cde | shift |
| 8 | aAbc | de | shift |
| 9 | aA | de | reduce using A → Abc |
| 10 | aAd | e | shift |
| 11 | aAB | e | reduce using B → d |
| 12 | aABe | shift | |
| 13 | S | reduce using S → aABe |
The above example shows how bottom-up parsing works on a small instance.
However, to formally define a bottom-up parser, we need to generalize this procedure to all grammars. Many details will be discussed.
Even within this small example, careful reader may find the above procedure has some problems.
In Step2, we read b. Then, we immediately reduce 𝑏 to A in Step3.
But the thing is different in Step4. We read b again, but the parser waits until it reads another c and reduces Abc to A.
In general, similar to the predictive parser, there might be multiple options in bottom-up parsing. We need to clearly define which option is used under a certain condition.
LR Parsing Algorithm
LR Parser
There are many different ways to solve the above problem, like using recursions (Same as what we did in the predictive parsing, recursions simply enumerate all possible options.)
In this course, we only introduce
- They are the most powerful non-backtracking shift-reduce parsers;
- they can be implemented very efficiently; and
- they are strictly more powerful than
When a reduction is performed, the
The parser puts state symbols into the stack to speedup checking the content on the stack.
Imaging that you want to check what’s on the given stack. You need to pop everything out, see if the content is same as what you want, then push everything back. This is very inefficient.
Thus, we use a state symbol to indicate the current content on the stack.
This symbol is called state symbol because it is exactly same the states in a DFA.
We can consider each state in a DFA means that "To reach this state, the input must be some specific strings."
Also, each
To parse a
This parsing table again enumerates the actions the parser needs to take in all possible situations.
Each row in the table represents a state in PDA.
The columns are split into two individual fields: ACTION and GOTO.
- Each column in ACTION represents a terminal.
- Each column in GOTO represents a nonterminal.
- The value of the entry ACTION
- The value are of two types:
- The value of the entry
- Put the special symbol $ at the end of the input.
- Put state 0 at the bottom of the stack.
- In each iteration, suppose the current configuration is
- If
- If
- If
- For all other cases, like
- If
Example
| State | id | + | * | ( | ) | $ | E | T | F |
|---|---|---|---|---|---|---|---|---|---|
| 0 | s5 | s4 | 1 | 2 | 3 | ||||
| 1 | s6 | acc | |||||||
| 2 | r2 | s7 | r2 | r2 | |||||
| 3 | r4 | r4 | r4 | r4 | |||||
| 4 | s5 | s4 | 8 | 2 | 3 | ||||
| 5 | r6 | r6 | r6 | r6 | |||||
| 6 | s5 | s4 | 9 | 3 | |||||
| 7 | s5 | s4 | 10 | ||||||
| 8 | s6 | s11 | |||||||
| 9 | r1 | s7 | r1 | r1 | |||||
| 10 | r3 | r3 | r3 | r3 | |||||
| 11 | r5 | r5 | r5 | r5 |
| Stack | Input | Output |
|---|---|---|
| 0 | id + id * id$ |
|
0id 5 |
+ id * id$ |
shift 5 |
0F 3 |
+ id * id$ |
reduce F → id |
0T 2 |
+ id * id$ |
reduce T → F |
0E 1 |
+ id * id$ |
reduce E → T |
0E 1 + 6 |
id * id$ |
shift 6 |
0E 1 + 6 id 5 |
* id$ |
shift 5 |
0E 1 + 6 F 3 |
* id$ |
reduce F → id |
0E 1 + 6 T 9 |
* id$ |
reduce T → F |
0E 1 + 6 T 9 * 7 |
id$ |
shift 7 |
0E 1 + 6 T 9 * 7 id 5 |
$ |
shift 5 |
0E 1 + 6 T 9 * 7 F 10 |
$ |
reduce F → id |
0E 1 + 6 T 9 |
$ |
reduce T → T * F |
0E 1 |
$ |
reduce E → E + T |
0E 1 |
$ |
accept |
SLR Parsing
Previously, we have introduced the
Now, the question is how to construct a parsing table for a given context-free grammar.
In fact, there are many ways to construct a parsing table for different 𝐿𝑅 parsers:
For
We will focus on
SLR Parser
To construct an
- augment the context-free grammar;
- construct a DFA based on the computation of set of items;
- represent the DFA using the transition table;
The construction in
Augmented Grammar
Given a grammar with a start symbol
we construct the corresponding augmented grammar by artificially introducing a nonterminal
This artificial production rule seems to be useless, but it guarantees that the parser accepts the input when it reduces using
The
An
- For example, the production
As a special case, the production
Each item represents a state that the parser is currently in.
If the parser is in the state corresponding to
If
Thus, the parser state corresponds to
Closure of items
Keep this intuition in mind, we find the closure of a set of items
-
Every item in
-
If
-
Repeat the above two steps until
-
For example,
Goto Function
Then, we define
For all the items of the form
-
For example, given the set of items
- the item
- the item
- the item
-
Thus,
更新时,当一个token 时non-terminal 时,继续传递
Set of items
Set of items construction algorithm
Next, we construct the DFA to decide the tokens in the stack.
This method is called set-of-items construction algorithm.
Each set of items
- Compute
- While there is an unmarked DFA state
- For each grammar symbol
- Compute the DFA state
- If
- If
- Compute the DFA state
- Mark
- For each grammar symbol
Example
For example,
Initially,
Then, we consider the
- For
| Production | Goto Symbol: |
|---|---|
Thus,
Similarly,
- DFA
In the following,
Consider the
We continue computing the
In the last iteration
Here is the list of sets of items.
| i | |
|---|---|
| 0 | |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 |
Set of items construction algorithm
In the DFA we constructed above, we don’t need final states.
Because we use states to show the content in the stack.
And the stack is reduced if DFA reaches a final state.
More interestingly, a state, together with the string to reach the state, form a pair in the configuration.
To SLR parsing table
First, we construct the
- If
- If
- If
For item 2, we give a number to each grammar production
Then, we construction the
- If
Summary
Here are the steps to create a parsing table for an
- Eliminate any ambiguity from the grammar.
- Eliminate left recursion from the grammar.
- Left factor the grammar.
- Augment the grammar with a new start symbol.
- Compute the sets of items for the grammar and build the corresponding DFA.
- Number the grammar productions.
- Compute the
- Compute the
- Use the sets of items, DFA, and the
Other Bottom-Up Parsing
In fact,
Consider the following ambiguous grammar.
Construct the set of items
In addition,
Thus, the parsing table construction algorithm will put both =
Sometimes, when current state is
To eliminate the conflict, we analyze the above grammar.
Then, we can see reduce(R → L) is not supposed to be performed in all the cases when the next input token is in FOLLOW(R).
- If
Lappears on the LHS of=,reduce(R → L)is only needed when there is a*beforeL. - And if an
Lis on the RHS of=, this specificLcan only be followed by$, but not=.
For example, if the input is * id = id, the parsing is as follows:
· * id = id→shift* · id = id→shift* id · = id→shift* L · = id→reduce(L → id)* R · = id→reduce(R → L)(highlighted in red)L · = id→reduce(L → * R)L = · id→shiftL = id ·→shiftL = L ·→reduce(L → id)L = R ·→reduce(L → R)(highlighted in red)S ·→reduce(S → L = R)
In addition to
For example,
This additional token does not do anything in most cases.
Only for the items in the type
Thus,
For other tokens in
Therefore, one state in the DFA for
For the previous grammar, the state which has
- one has
- and the other has
However, even the parsing table is upgraded in this way, some grammar can still create shift–reduce conflict.
Then, we can let each
This upgrading process can continue and define an
Instead of trying to solve more problems but creating chaos, sometimes we want to ignore some problems and keep our life easier.
Thus, LALR(1) item is introduced.
Consider two
- An
- This undoes the splitting from
- The merging reduces the number of states and loses very little power.
Back to the example,