date: 2024-11-20
title: Compiler Semantic Analysis
status: DONE
author:
- AllenYGY
tags:
- NOTE
- Compiler
- SemanticAnalysis
publish: trueCompiler Semantic Analysis
- Semantic rules
- Syntax-directed definition
- Attribute grammar
- Synthesized attribute
- Inherited attribute
- Syntax tree
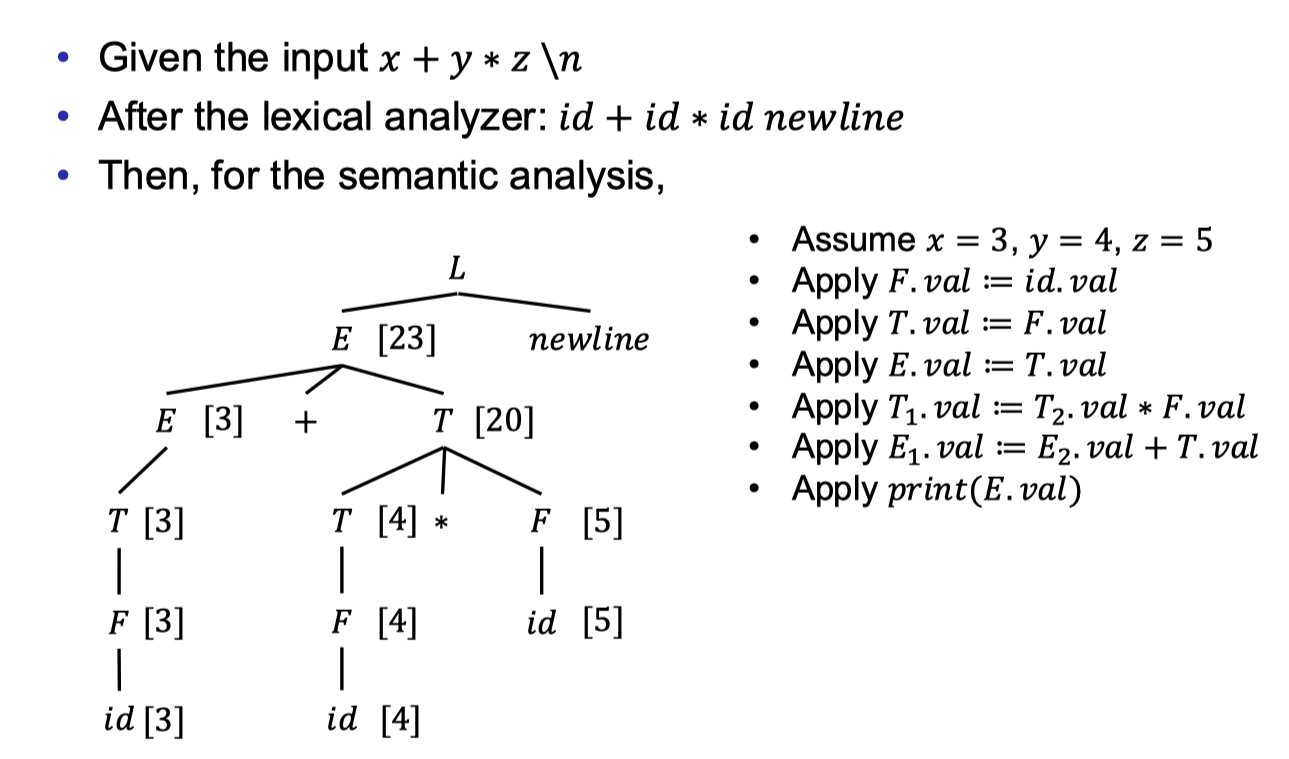
After syntax analysis, the next phase is semantic analysis and intermediate code generation.
The two steps are all based on syntax-directed translation, which is procedure to compute the attribute of each grammar symbol in a syntax-tree.
To compute the attributes, we use attribute computation functions, also called semantic rules.
Each grammar production rule has zero or multiple semantic rules to compute the attributes.
The attributes can record a lot of information that a compiler wants to know, for example the values of a math expression, the type of a variable, etc.
Semantic rules
Two different ways to specify the semantic rules in syntax directed translation:
- Translation schemes
- specify the order to compute the attributes.
- Syntax-directed definitions
- do not specify the order to compute the attributes.
Syntax-directed definitions are more flexible and easier to understand.
Syntax-directed definition
In syntax-directed definitions, attributes are of two types:
- Synthesized attributes: computed bottom-up in a parse tree.
- Inherited attributes: computed top-down and left-right or right-left in a parse tree.
合成属性 自底向上计算属性
继承属性 自顶向下,从左至右或从右至左计算属性
Synthesized attributes
For a grammar production
语义规则的形式 :这里的
-
The attribute of
换句话说,在一棵语法树中,父节点的属性仅取决于其子节点的属性。 -
The symbol
这说明 综合属性是自下而上的计算过程,因为必须先计算子节点的属性,才能计算父节点的属性。
In other words, in a parse tree, the attribute
综合属性遵循 自下而上(bottom-up) 的计算模式,这与语法分析中语法树的构建过程密切相关。例如,在语法分析中,叶子节点的值(通常是终结符的属性)被逐步向上传递,最终计算根节点的属性。
Inherited attribute
On the other hand, an inherited attribute is computed by
-
The attribute
-
Different from synthesized attributes, which is a grammar symbol on the LHS.
-
- all attributes of other symbols in the RHS,
- the attribute of the symbol on the LHS.
-
In a parse tree,
The order to compute the attributes of all siblings is unclear.
Intrinsic Attributes
The computation of synthesized attributes is in fact a recursion.
For every grammar symbol
-
If
Following the recursion,
-
If
Thus, synthesized attributes for tokens are called intrinsic.
Meaning that they are not computed by any semantic rule.
Attribute grammar
In both the synthesized and inherited cases, the attribute computation function
- a function: only has outputs but no side effects; or
- a procedure: only has side effects but no outputs.
If all semantic rules in syntax-directed definitions are functions, then the syntax-directed definitions and the corresponding grammar productions together form an attribute grammar.
Which is a special case of syntax-directed definition.
语法制导定义(Syntax-Directed Definitions, SDD):
- 定义语法与语义规则之间的关系。
- 语义规则可以是函数或过程。
属性文法(Attribute Grammar, AG):
- 如果语法制导定义中的所有语义规则都是函数(即没有副作用),则语法制导定义与文法规则结合就构成了属性文法。
- 属性文法是一种语法制导定义的特殊情况,具有更强的确定性和可分析性。
S-attributed definitions
In semantic rules, if all the attributed are synthesized, then the syntax-directed definitions are called
换句话说,𝑆-attributed定义是指向语法的定义,其所有属性都可以在解析树中自下而上地计算。
- For implementation interests, if a compiler uses an
Synthesize
Here is an example of
Syntax Rules and Attribute Definitions
Note:
- In rule 2, the symbol
- In syntax rule 2, "+" is a token returned by the lexical analyzer. But in semantic rule 2, "+" is purely semantic, which is an arithmetic operator predefined in the compiler. Same as rule 4.
Inherited
Inherited Attributes Example
Think about a sequence of variable definitions like int x,y,z.
The production rules can be easily defined as
And the compiler wants to check the type for each variable.
Synthesized attributes do not work in this example.
The attributes for the tokens derived by
Thus, inherited attributes are used here.
Note that
- All
The semantic rule 4 does two things: pass the attribute
Thus, the above syntax-directed definitions are
Syntax tree
Syntax trees are tractive in implementations because
they are much smaller than parse trees, and they only depends on the source program, but not the grammars.
Many compilers use syntax tree to represent the intermediate code instead of three-address code.
Given the following grammar and the corresponding
The attributes in the above cases are intrinsic.
We also use a synthesized
Evaluation of Attributes
For
For
Remember synthesized attributes are computed in the bottom-up order.
We do not need an individual phase for semantic analysis.
The attributes are computed at the same time with parsing.
- If the parser shifts a token from the input onto the stack, then the associated attribute is intrinsic. Thus, the attribute comes from the lexer or the corresponding entry in the symbol table.
- If the parser reduces the top of the stack, then the attribute is computed by the semantic rule.
For
For
Remember that inherited attributes have to be computed top-down, left-right, or right-left.
Infeasible to be done at the same time as parsing.
Therefore, it needs another phase for
Sometimes, the computation can be very chaotic when
- some of the attributes are computed left-right,
- some are right-left,
- some other can even be in a dynamic order (case dependent).
That’s why people usually try to avoid using inherited attributes.
But sometimes the inherited attributes are unavoidable.
Fortunately, there is a one case that the computation is tractable, when all attributes can be computed in a single depth-first traversal.
DFS(A){
Evaluate the inherited attributes of A
For each child $X_i$ of $A$ (from left to right) do {
DFS($X_i$)
}
Evaluate the synthesized attributes of A
}
The depth-first traversal can also be presented in a parse tree.
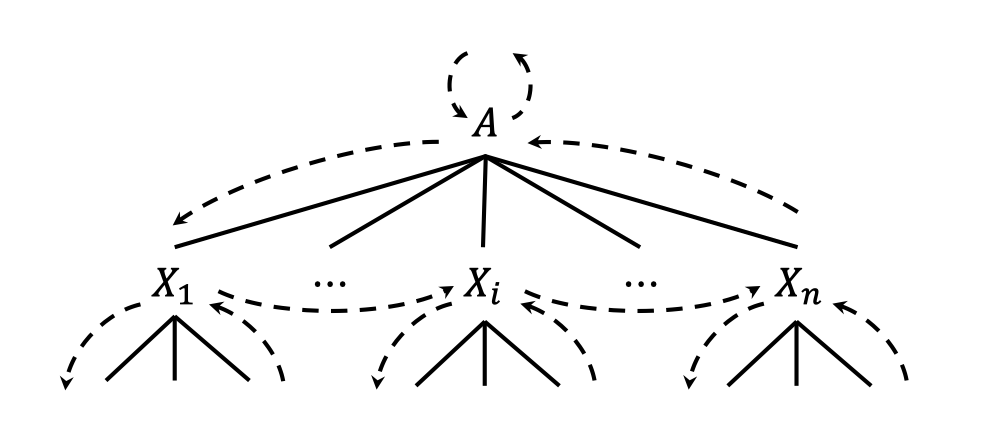
If all synthesized and inherited attributes of the syntax-directed definitions can be computed in a single depth-first traversal, the definitions are called
Note that all
Semantic Analysis
Semantic Analysis is the last phase in the front-end.
This phase commonly checks
- is every variable and function defined before it is used?
- is every variable initialized before it is used?
- Are all expressions and statements in the correct type?
This course only focus on type checking using synthesized attributes.
Thus, this can be done by a simple bottom-up computation together with parsing.
To keep our life easier, we only stick with simple programming languages, like C.
We won’t discuss advanced features like classes or polymorphism in OOPs.
Type check these advanced features cannot be done by easily using attributes.
Type Checking
The goal of type checking is to compute a type for each expression and statement in a program.
And check that all these types are coherent.
- If some types are inconsistent then the type checker should inform the user about the error.
- If all types are correct, then the parse tree will be converted to the intermediate code.
A type is a syntactic description of a set of possible runtime values.
"Syntactic" means that a type is only a syntax, given by the source program.
At compile time, the type checker gives a meaning to the syntax, which is a set of values.
The values that the corresponding expression is allowed to have when the program is running.
And thus, types do not exist at runtime.
At runtime, the microprocessor only manipulates bits in the memory.
For examples, 110101011 is only a bit string. Microprocessors cannot know if string represents a float, an integer, a pointer, or other things.
Some programming languages, like Python or php, do not have types.
Compilers/Interpreters for these languages do not to type checking at all.
In these languages, each value has an extra tag at runtime.
Which describes what kind of value the program is dealing with.
Different Types
There are two kinds of types:
- Basic types (or primitive types, or atomic types)
- Simplest types which cannot be split further.
- Only to those values directly supported by microprocessors
- Like, char, int, long, float, etc.
- Constructed types
- Made of combinations of smaller types.
- Can be split into basic types.
- Like, array, structures, pointers, etc.
Type Expressions
A type expression is the internal representation of a type inside the compiler.
Compilers use type expressions to represent the types of statements in the source program.
The type checker computes a type expression for each expression in the source program.
- Starts from the types specified by the programmer in the source code.
- Transforms them into type expressions.
- Combines the type expression in different ways to compute type expressions for other statements.
Different Type Expressions
Basic type expressions
- directly represent the basic types
- they are atomic
- e.g. character, integer, boolean, etc.
type_error
- a special basic type
- representing an error detected during type checking
void
- a special basic type
- representing the absence of a type
- for pieces of programs that we do not compute a value
Type Systems
Typing Rules
Let’s look at our first typing rules.
Given the following grammar for a small programming language.
A program in this language is a sequence of variable definitions followed by a single expression.
The type for a variable can be a basic type, like char or int.
It can also be a constructed type, like pointer.