date: 2024-03-19
title: 04-Threads
status: DONE
tags:
- OS
- NOTE
- Lec4
author:
- AllenYGY
created: 2024-03-20T17:14
updated: 2024-04-08T22:57
publish: TrueThreads
Process vs. Thread
Thread
A thread is a single sequence stream within a process.
The threads of a process share resources at any given time.
Resources including
- executable code
- the values of its variables
code section, data section, OS resources
Most modern applications are multi-threaded
- Kernels are generally multi-threaded
Multiple tasks in an application can be implemented by separate threads
- Example: The following tasks can do in an application:
- Update display
- Fetch data
- Spell checking
- Answer a network request
- Economy
- Process creation: heavy-weight
- Thread creation: light-weight
- Resource Sharing
- Efficiency
- Can simplify code
- Responsiveness
- May allow continued execution if part of process is blocked
- 即使进程的部分被阻塞,仍可以继续运行
- Scalability
- Process can take advantage of multicore architectures, with one or two threads per core
More difficult to program with threads
New categories of bug are possible
Threads vs. Processes
- Threads share CPU and only one thread active (running) at a time.
在一个进程中 - Threads within a processes execute sequentially.
- Thread can create children.
- If one thread is blocked, another thread can run.
- A thread is a component of a process
- Multiple threads can exist within one process.
- Multiple threads execute concurrently and share resources such as memory, while different processes do not share these resources.
| Processes | Threads |
|---|---|
| Typically independent | Subsets of a process |
| More state information | Share process state and resources |
| Separate address spaces | Same address space |
| Interact throughIPC models: (shared memory/message passing) | Variables |
| Slower context switching | Faster context switching |
| Might or might not assist one another | Designed to assist one another |
Multicore Programming
Multi-core or multi-processor systems putting pressure on programmers
Challenges include:
- Dividing activities
- Load Balance Data splitting
- Data dependency
- Testing and debugging
Concurrency vs. Parallelism
并发- More than one task are progressing
- Single processor / core, CPU scheduler providing concurrency by doing context switches
- 两个事件或多个事件在同一时间间隔内发生。事件在宏观上同时发生,但微观上是交替发生的

并行- More than one task are progressing
- Single processor / core, CPU scheduler providing concurrency by doing context switches
- 指两个或者多个事件在同一时刻同时发生

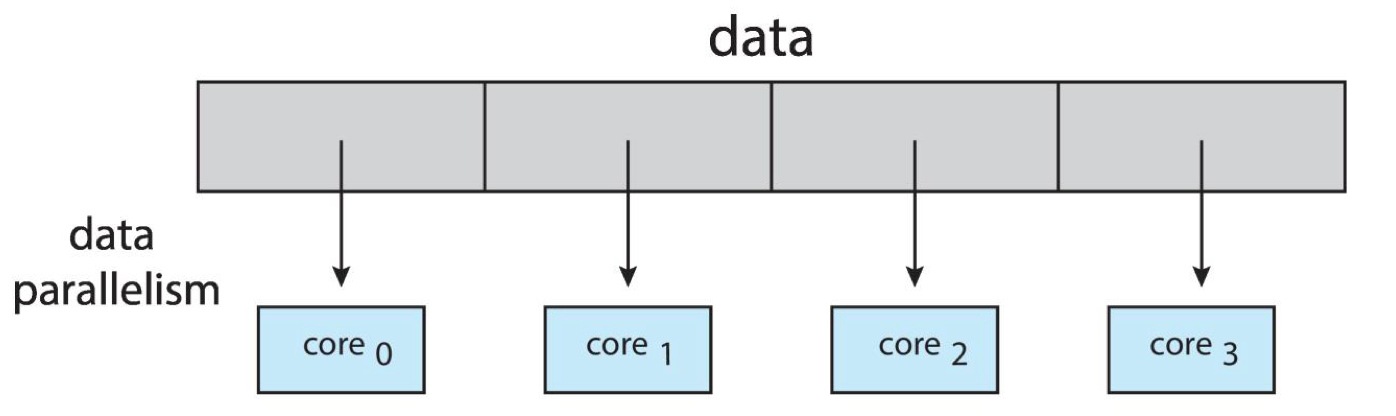
- Data parallelism – distributes subsets of the same data across multiple cores, same operation on each
- Example: when doing image processing, two cores can each process half of the image
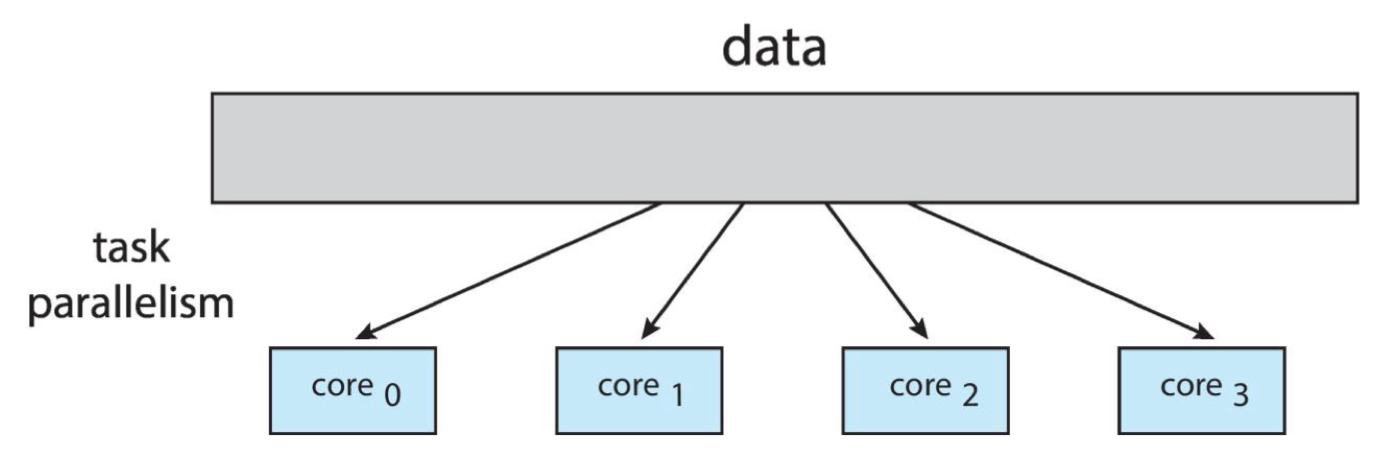
- Task parallelism – distributing threads across cores, each thread performing unique operation
- Example: when doing sound processing, the sound data can move through each core in sequence, with each core doing a different kind of sound processing (filtering, echo, etc.)
Amdahl’s Law
Identifies performance gains from adding additional cores to an application that has both serial and parallel components
它是用来估计在给定部分程序能够并行化的前提下,多处理器系统相比于单处理器系统在执行该程序时能达到的最大加速比。
- S is serial portion
串行部分
Sis serial portion,Pis parallel portion of program.
SoS + P = = 1- Assume that running time on one core:
- Then running time on
Ncores:
(≥, not =, because of extra communication required between threads.) - Therefore,
Gustafson’s Law
Gustafson's law addresses the shortcomings of Amdahl’s law
It is based on the assumption of a fixed problem size
N,S,P: meanings are same as in Amdahl algorithm.
Gustafson's Law强调了随着问题规模的增加,可以实现更高的并行度
Amdahl's Law则强调了并行计算的理论上限。两者都在并行计算领域提供了重要的视角。
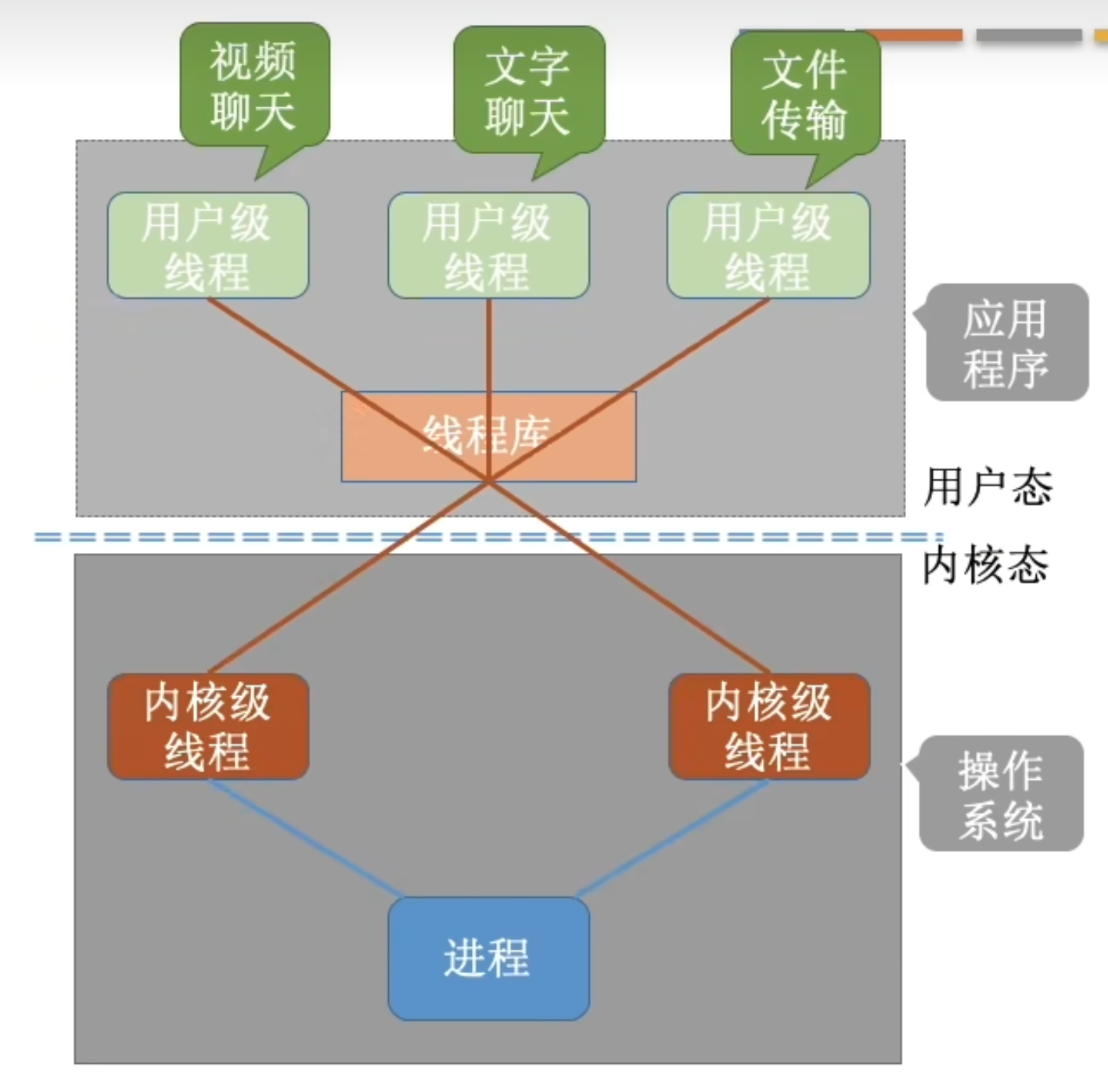
User Threads and Kernel Threads
User Threads
Management[1] done by user-level threads library.
No need for OS support
Works even on very old or very simple OS that does not have system calls for thread management.
No system call required
Fast: only need a library function call.
- A process with only one thread gets as much CPU time as a process with many threads.
分配不合理 - All the thread scheduling inside a process must be done at user level (not done by kernel)
- Each thread must be nice and cooperate with the other threads in the process and regularly give CPU time to the other threads.
- Program more complicated to write.
Kernel Threads
Management[2] supported by the kernel
Kernel Threads 是处理机分配的单位
Kernel knows how many threads each process contains so it can give more CPU time to the processes with many threads. Kernel更好分配任务
- No need for threads to cooperate for scheduling
- Thread scheduling done automatically by kernel
- User program simpler to write.
Every thread management operation requires a system call
Slower compared to user-level threads.
Kernel’s PCB data structures more complex
- The kernel needs to keep track of both processes and threads inside processes.
Multithreading Models
- Many-to-One
- One-to-One
- Many-to-Many
Many-to-One
- Many user-level threads mapped to single kernel thread.
- One thread blocking (waiting for something) causes all threads to block (because their common kernel thread is blocked).
- Multiple threads may not run in parallel on multicore system because only one may be in kernel at a time.
- Examples: 1. Solaris Green Threads 2. GNU Portable Threads
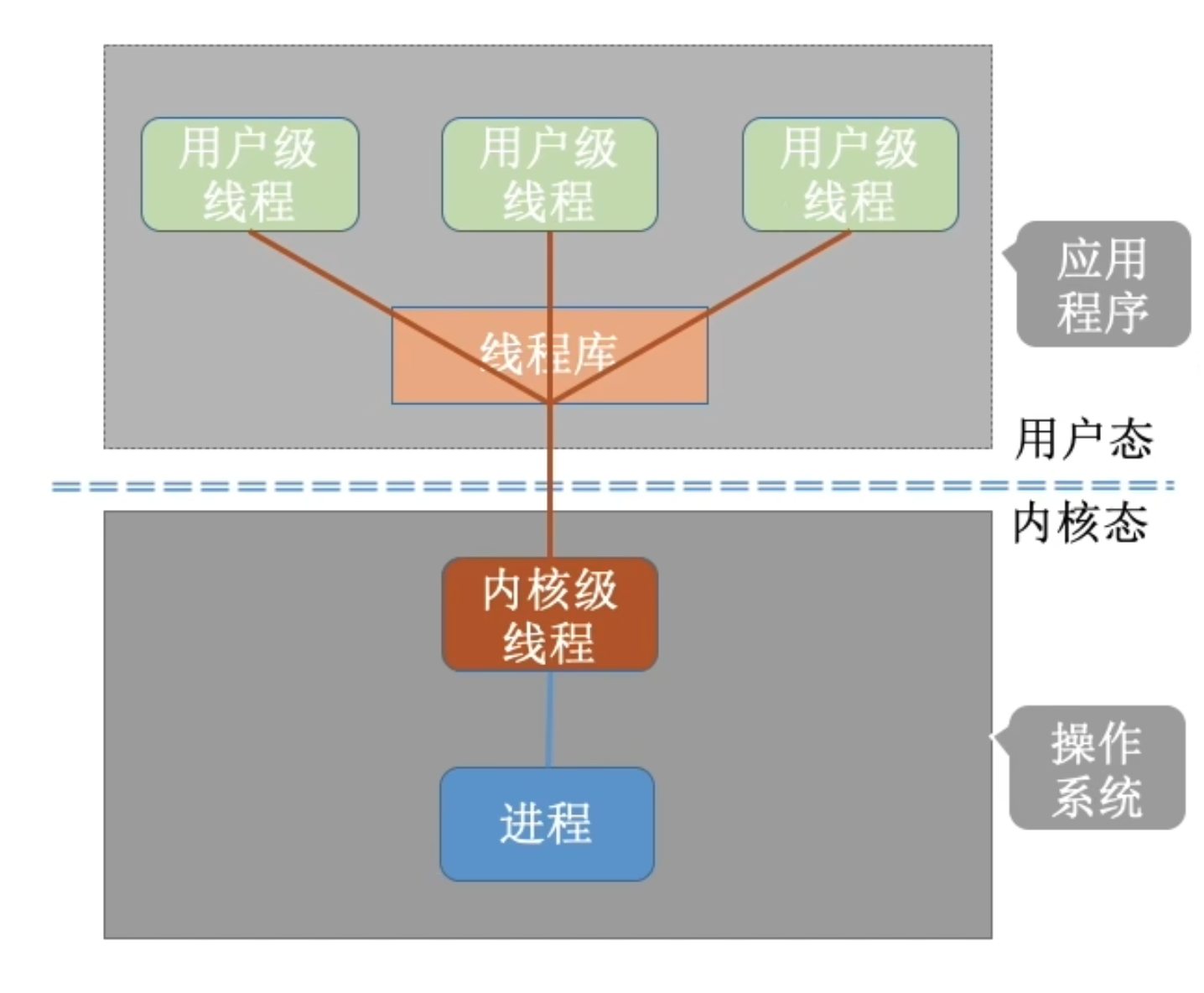
Few systems currently use this model.
One-to-One
- Each user-level thread maps to kernel thread.
- Creating a user-level thread creates a kernel thread.
- More concurrency than many-to-one.
- Number of threads per process sometimes restricted due to overhead.
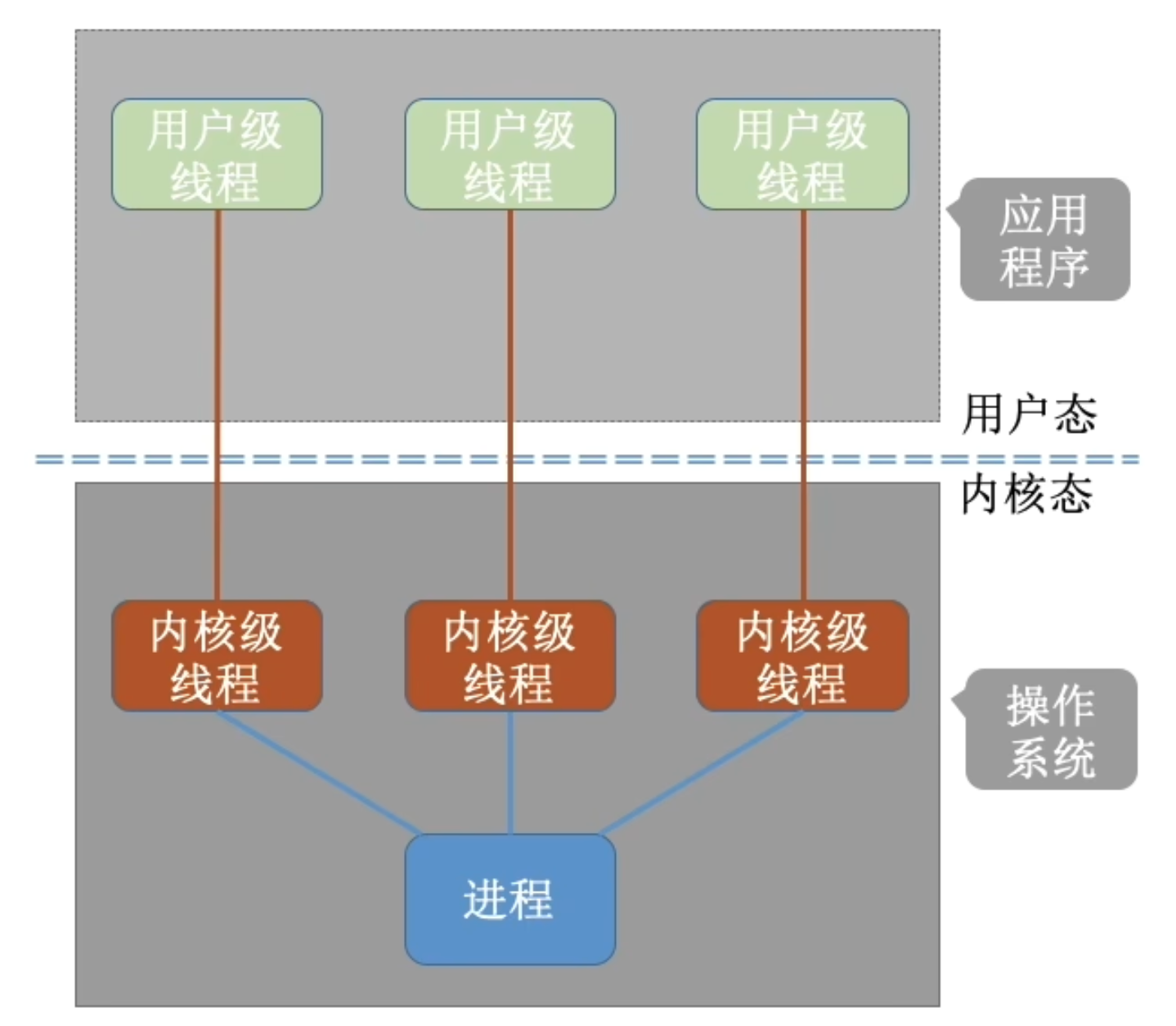
需要在用户态和内核态切换,开销大
- Windows and Linux use this model
Many-to-Many
- Allows many user level threads to be mapped to many kernel threads.
- Allows the operating system to create a sufficient number of kernel threads.
- Example: Windows with the ThreadFiber package. Otherwise not very common.
Thread Libraries
Thread library provides programmer with API for creating and managing threads
Library entirely in user space (user threads only)
OS-level library supported by the kernel (user threads mapped to kernel threads, with one-to-one model for example).
- POSIX Pthreads
- Windows threads
- Java threads
Pthreads
May be provided either as user-level or kernel-level
A POSIX standard (IEEE 1003.1c) API for thread creation and synchronization
- Specification, not implementation
- API specifies behavior of the thread library, implementation is up to developers of the library
Common in UNIX operating systems (Linux & Mac OS X)
Implicit Threading
Implicit threading是一种编程方法,其中并行性是由编译器、运行时系统或其他并行编程框架自动管理的,而不是由程序员显式控制。
Thread Pools
Create a number of threads in advance in a pool where they await work
- Advantages:
- Usually slightly faster to service a request with an existing thread than create a new thread
- Allows the number of threads in the application(s) to be bound to the size of the pool
- Separating task to be performed from mechanics of creating task allows different strategies for running task
- Windows API supports thread pools:
- Available in Java as well
-
初始化:创建一个线程池,指定线程数量,通常基于可用的CPU核心数。
-
任务提交:任务提交给线程池,而不是直接提交给某个线程。这些任务通常保持在一个队列中。
-
任务执行:线程池中的空闲线程从队列中提取任务并执行。一旦线程完成了任务,它就可以用于另一个任务。
-
优势:这样可以避免为每个任务创建和销毁线程的开销,这种开销可能很大。它还允许更好地控制活跃线程的数量,防止系统因为太多并发线程而过载。
-
使用场景:线程池被用于服务器应用程序处理多个客户端连接,在工作队列管理中,以及任何任务可能成批出现并需要由限定数量的工作人员处理的情况。
线程池是隐式线程的一种形式,因为程序员不直接管理线程生命周期或任务到线程的分配。相反,他们使用池和任务的更高级别抽象,而底层实现处理线程管理的细节。
Fork-Join Parallelism
Multiple threads (tasks) are forked, and then joined.
- Available in Java. (since Java SE7)
- Similar to Hadoop MapReduce operation
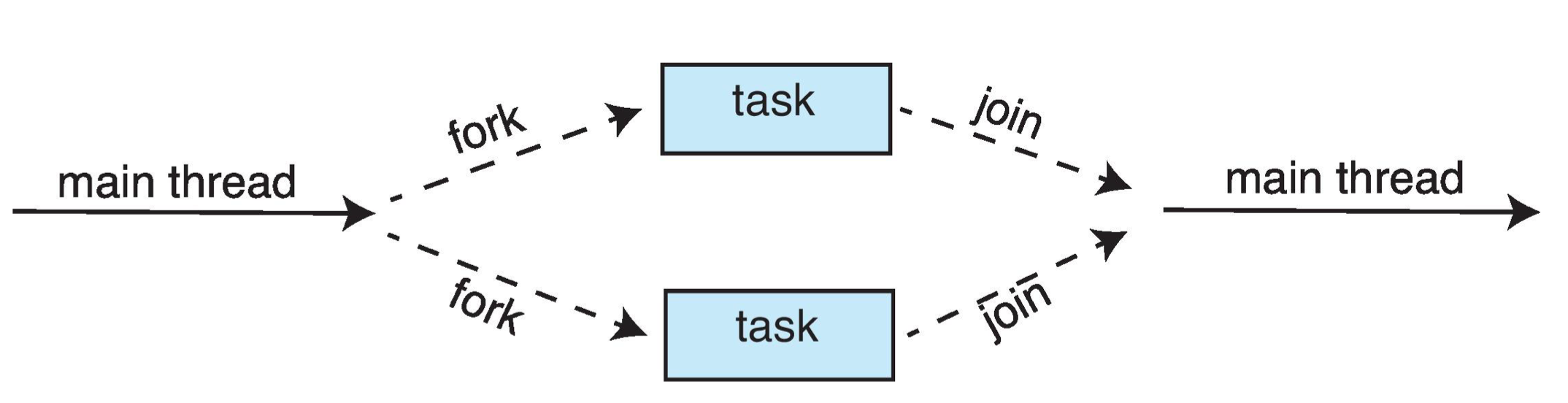
Fork-Join并行模型是一种实现并行处理的编程模式,特别适合于可以递归分解为更小问题的任务。这个模式通常是通过一种显式的方式使用的,但由于其高级的抽象性,它在某些上下文中也可以被看作是隐式线程的一种形式。
Fork-Join模型解释:
在Fork-Join模型中,主要的思想是将一个大的任务分解(Fork)成若干个小任务,这些小任务可以并行处理,处理完毕后再将结果合并(Join)起来。这种模型特别适合处理可以递归分解的问题,比如快速排序、归并排序、图像处理等。
Fork-Join并行模式通常在编程中通过特定的库(如Java中的java.util.concurrent库)来实现,这些库提供了创建任务、同步、以及合并结果的API。程序员需要明确地创建任务,并指定任务之间的分解和合并逻辑。
为什么Fork-Join有时候被看作隐式线程:
虽然Fork-Join模型通常需要程序员明确指定任务的拆分和合并,但是在一些现代编程框架中,如Java的Fork/Join框架,程序员不需要直接管理线程,而是通过高层次的任务(比如RecursiveAction和RecursiveTask)来表达并行逻辑。这些任务被提交到一个可以管理这些任务并自动处理线程分配和同步的线程池。在这个意义上,尽管Fork-Join模型需要程序员做一些并行设计,但线程的具体管理是由框架隐式完成的,所以可以认为这有隐式线程的特征。
OpenMP
Set of compiler directives and an API for C, C++, FORTRAN
Provides support for parallel programming in shared-memory environments
Identifies parallel regions – blocks of code that can run in parallel
OpenMP(Open Multi-Processing)是一个支持多平台共享内存并行编程的应用程序接口(API),其目的是为高性能计算提供一个便捷的方式来编写多线程的应用程序。它定义了一系列编译器指令、运行时库调用和环境变量,这些可以被用来指定高级别的并行性,无需程序员直接管理线程。
主要特点:
-
跨平台:OpenMP可以在包括UNIX和Windows操作系统在内的多种平台上使用。
-
简易性:通过编译器指令(通常称为pragma),程序员可以轻松地将串行代码并行化。例如,在C/C++中,一个简单的
#pragma omp parallel就能够将代码块内的指令并行执行。 -
灵活性:OpenMP允许程序员详细控制线程行为,例如分配和管理数据,以及优化并行执行的性能。
-
可扩展性:OpenMP可以根据可用的处理器核心数自动调整并行任务的数量。
如何工作:
-
并行区域:使用
#pragma omp parallel创建并行区域,该区域内的代码将被多个线程并行执行。 -
循环并行化:对于迭代计算,可以使用
#pragma omp for或#pragma omp parallel for指令来分配循环迭代给不同的线程。 -
任务并行化:OpenMP 3.0及以后的版本支持任务并行,允许程序创建可以独立于循环并行化的异步任务。
-
同步机制:OpenMP提供了多种同步机制,如屏障(
#pragma omp barrier)、临界区(#pragma omp critical)和原子操作(#pragma omp atomic),用以控制线程间的执行顺序和数据访问。 -
数据环境:可以使用
#pragma omp指令的子句来管理数据的作用域(共享或私有)。
OpenMP是一个成熟的API,被广泛应用于科学计算、工程模拟和数据分析等领域。由于它提供了一种高层次的抽象,并能自动处理许多与线程管理相关的复杂性,因此可以认为它在某种程度上提供了隐式线程管理。即使是在并行区域中,大部分的线程管理和同步工作都是自动完成的,使得开发者可以专注于算法的并行化,而不必深入底层的线程管理细节。
Thread-Local Storage(TLS)
- Thread-local storage (TLS) allows each thread to have its own copy of data
- Useful when you do not have control over the thread creation process (i.e., when using a thread pool)
- Different from local variables Local variables visible only during single function invocation
- TLS visible across function invocations Similar to static data
- TLS is unique to each thread
Linux declare a TLS variable:
_ _thread int number;
Thread Cancellation
Terminating a thread before it has finished Thread to be canceled is target thread Two general approaches:
-
Asynchronous cancellation terminates the target thread immediately
异步取消会立即终止目标线程 -
Deferred cancellation allows the target thread to periodically check if it should be cancelled
延迟取消允许目标线程定期检查是否应该取消
Invoking thread cancellation requests cancellation, but actual cancellation depends on thread state
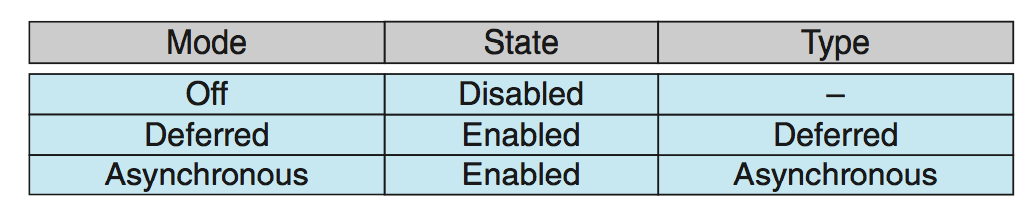
If thread has cancellation disabled, cancellation remains pending until thread enables it
Default type is deferred
- Cancellation only occurs when thread reaches cancellation point
- i.e. pthread_testcancel()
- Then cleanup handler is invoked
- Windows API – primary API for Windows applications
- Implements the one-to-one mapping, kernel-level
- Each thread contains
- A thread id
- Register set representing state of processor
- Separate user and kernel stacks for when thread runs in user mode or kernel mode
- Private data storage area used by run-time libraries and dynamic link libraries (DLLs)
- The register set, stacks, and private data storage area are known as the context of the thread
- thread creation, thread scheduling, etc.↩︎
- thread creation, thread scheduling, etc.↩︎
- a technology developed by Apple Inc. to optimize application support for systems with multi-core processors and other symmetric multiprocessing systems. It is an implementation of task parallelism based on the thread pool pattern.↩︎
- Threading Building Blocks (TBB) is a C++ template library developed by Intel for parallel programming on multi-core processors. Using TBB, a computation is broken down into tasks that can run in parallel. The library manages and schedules threads to execute these tasks.↩︎