date: 2024-03-19
title: 05-CPU Scheduling
status: DONE
tags:
- OS
- NOTE
- Lec5
author:
- AllenYGY
created: 2024-03-20T22:56
updated: 2024-04-11T16:11
publish: TrueCPU Scheduling
Basic Concept
To maximize CPU utilization
Using Multiprogramming
- Process execution consists of a cycle of CPU execution and I/O wait
- CPU burst followed by I/O burst
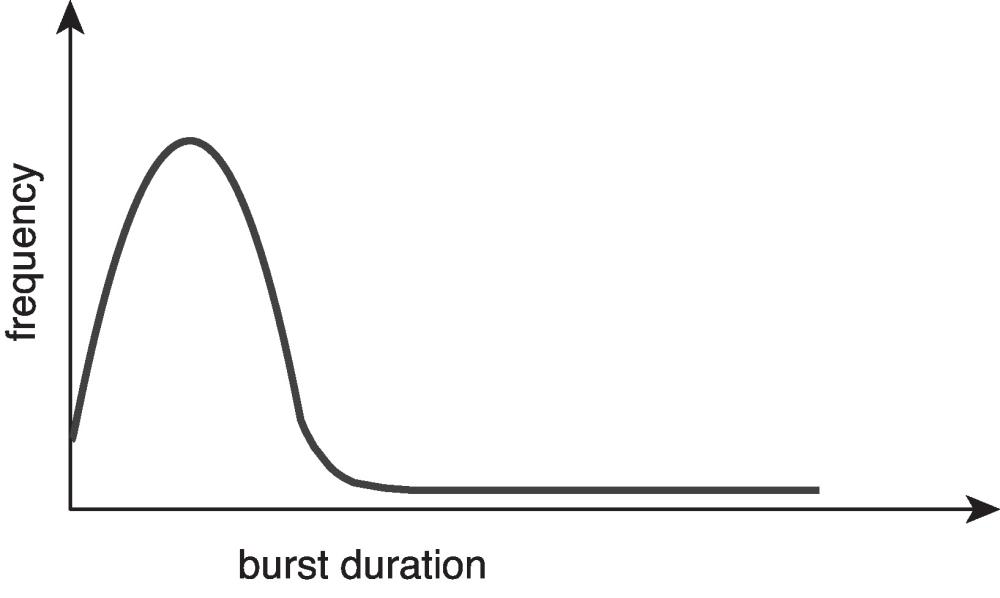
- 横轴表示CPU Burst时间
- 短CPU突发:大多数进程都会有大量的短时间CPU突发,这表示进程在执行较短时间的计算后就会等待I/O操作。
- 长CPU突发:只有少数进程会有较长时间的CPU突发,这些通常是计算密集型的进程,在执行更长时间的计算之后才会进行I/O操作。
CPU Scheduler CPU调度程序
- Ready queue
就绪队列may be ordered in various ways
- switches from running to waiting state (non-preemptive
自愿)- Example: the process does an I/O system call.
- switches from running to ready state (preemptive
非自愿)- Example: there is a clock interrupt.
- switches from waiting to ready (preemptive)
- Example: there is a hard disk controller interrupt because the I/O is finished.
- terminates (non-preemptive)
- When a process is pre-empted,
当进程非自愿离开CPU- It is moved from its current processor
- However, it still remains in memory and in ready queue
仍保留在就绪队列
- When a process is non-preemptive
当进程自愿离开CPU- Process runs until completion or until they yield control of a processor
进程运行直至完成或让出处理器控制权 - Disadvantage: Unimportant processes can block important ones indefinitely
进程易阻塞
- Process runs until completion or until they yield control of a processor
- Improve response times
- Create interactive environments (real-time)
Scheduling Criteria
- Throughput: number of processes that complete their execution per time unit
吞吐量 - Response Time: amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
等待时间-进程在就绪队列中等待的总时间 - Turnaround Time: amount of time to execute a particular process (from start to end of process, including waiting time)
执行特定流程的时间(从流程的开始到结束,包括等待时间)- Turnaround Time = Waiting time + time for all CPU bursts
Scheduling Algorithm
-
First-Come, First-Served
FCFS -
Shortest-Job-First
SJF -
Priority Scheduling
PS -
Round-Robin
RR -
Multilevel Queue Scheduling
MQS -
Multilevel Feedback Queue Scheduling
MFQS
First-Come, First-Served Scheduling FCFS
- Suppose that the processes arrive in the ready queue at time
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
- The Gantt Chart for the schedule is:

- Waiting time:
- Average waiting time:
- Average turnaround time:
Suppose the order is changed to this
- The Gantt Chart for the schedule is:

- Waiting time:
- Average waiting time:
- Average turnaround time:
护送效应 - short process behind long processShortest-Job-First Scheduling SJF
- SJF is optimal – gives minimum average waiting time for a given set of processes
- The difficulty is knowing the length of the next CPU request Could ask the user
| Process | Burst Time |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |
- The Gantt Chart for the schedule is:

- Average waiting time =
- Average turnaround time =
Determining Length of Next CPU Burst-duration.png
Use the length of previous CPU bursts, with exponential averaging
Shortest-remaining-time-first SRTF
The preemptive version of SJF is also called shortest-remaining-time-first
- Preemption: If a new process arrives in the ready queue while a current process is executing, the remaining time to complete the current process is compared with the total time required by the new process to finish. If the new process requires less time than what the current process has left, the current process is preempted (put back in the ready queue) and the CPU is given to the new process.
- Efficiency: This algorithm is effective in terms of average waiting time and turnaround time. By giving preference to processes that are closest to completion, it minimizes the amount of time each process has to wait to complete its execution.
- Starvation: A potential downside of SRTF is that longer processes may suffer starvation; if shorter processes keep arriving, the longer processes may be postponed indefinitely.
- Dynamic: Unlike SJF, which is static and decides on a process before it starts executing, SRTF has to make decisions dynamically as new processes arrive and as the remaining execution times of the processes in the ready queue change.
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 4 | 5 |
- The Gantt Chart for the schedule is:

- Average waiting time =
- Average turnaround time =
Round-Robin RR
- Each process gets a small unit of CPU time (time quantum
定额, usually 10-100 milliseconds. - After q has elapsed, the process is preempted by a clock interrupt and added to the end of the ready queue.
- Timer interrupts every quantum q to schedule next process
- If there are n processes in the ready queue and the time quantum is q. No process waits more than
- Performance
- q too large
- q too small
- q should be large compared to context switch time
- q usually 10ms to 100ms, context switch < 10 usec (微秒)
- q too large
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |

- Average waiting time:
- Average turnaround time:
Priority Scheduling
The CPU is allocated to the process with the highest priority
(smallest integer
- Preemptive
- the current process is pre-empted immediately by high priority process
- Non-preemptive
-the current process finishes its burst first, then scheduler chooses the process with highest priority
SJF is priority scheduling where priority is the inverse of predicted next CPU burst time
- Problem: Starvation: low priority processes may never execute
- Solution: Aging: as time progresses increase the priority of the process
| Process | Burst Time | Priority |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P5 | 5 | 2 |

Average waiting time =
| Process | Burst Time | Priority |
|---|---|---|
| P1 | 4 | 3 |
| P2 | 5 | 2 |
| P3 | 8 | 2 |
| P5 | 3 | 3 |

Average waiting time =
Multilevel Queue
- Ready queue is partitioned into separate queues, e.g.:
- Foreground (interactive processes)
- Background (batch processes)
- Process permanently in a given queue (stay in that queue) Each queue has its own scheduling algorithm:
- Foreground – RR
- Background – FCFS
- Scheduling must be done between the queues:
- Fixed priority scheduling
- Each queue has a given priority
- High priority queue is served before low priority queue
- Possibility of starvation
- Each queue has a given priority
- Time slice
- Each queue gets a certain amount of CPU time
- Fixed priority scheduling
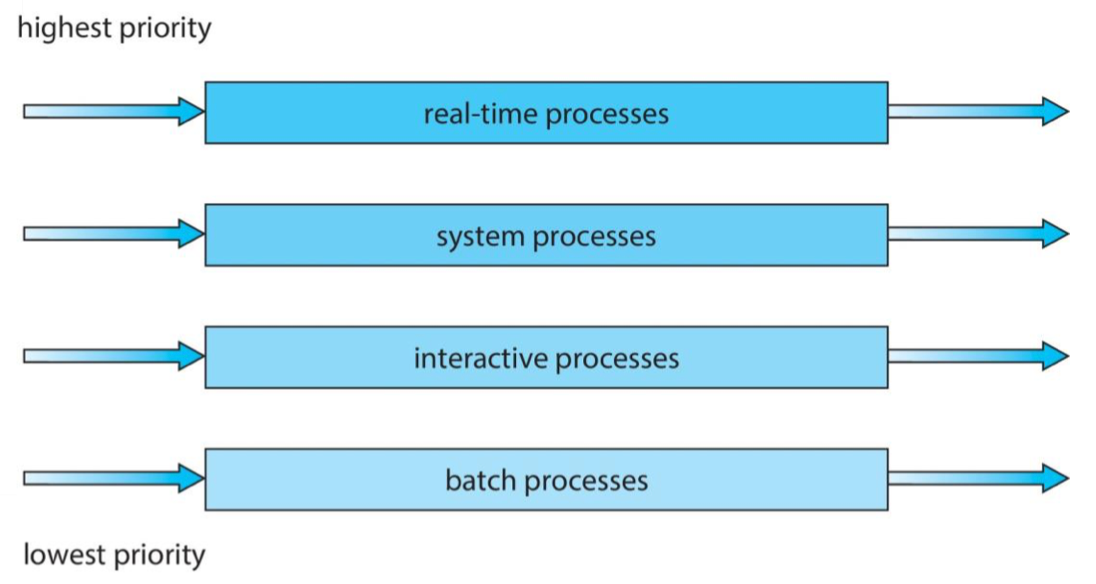
Multilevel Feedback Queue MFQ
- A process can move between the various queues;
- aging can be considered in this way (prevent starvation)
- advantage: prevent
- The multilevel feedback queue scheduler
- the most general CPU scheduling algorithm
- defined by the following parameters:
- number of queues
- scheduling algorithms for each queue
- Policies on moving process between queues
- when to upgrade a processes
- when to demote
降级a processes - which queue a process will enter when that process needs service
Three queues: FCFS+RR
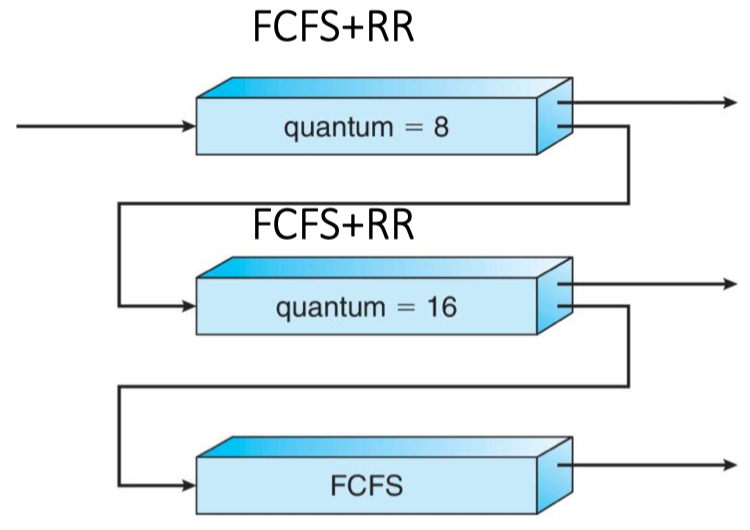
- A new job enters queue
- When it gains CPU, job receives 8 milliseconds
- If it does not finish in 8 milliseconds, job is moved to queue
- At
- If it still does not complete, it is preempted and moved to queue
Thread Scheduling
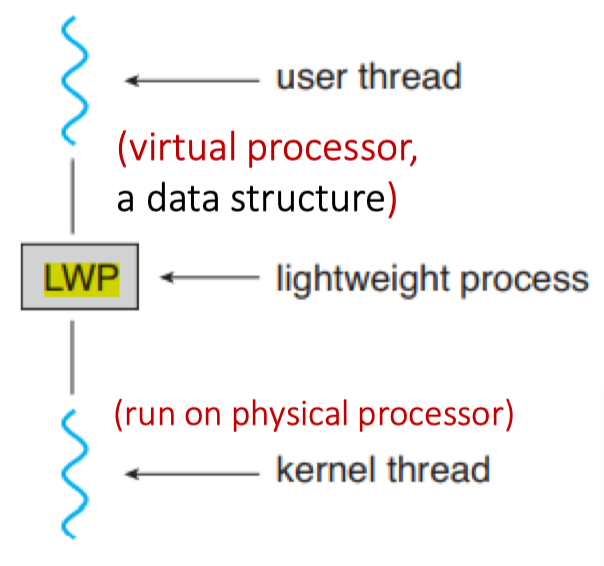
Distinguish between user-level and kernel-level threads
-
When threads are supported by kernel, threads are scheduled, not processes
当内核支持线程时,内核调度的是线程,而不是进程ExampleMany-to-one and many-to-many models,
- Thread library schedules user-level threads to run on kernel threads (LWP: light-weight process)
Typically priority is set by programmer
优先级人为设置 -
Kernel threads are scheduled by Kernel onto available CPU
内核线程被可利用的CPU调度- system-contention scope
SCS - competition is among all kernel-level threads from all processes in the system
- system-contention scope
-
-
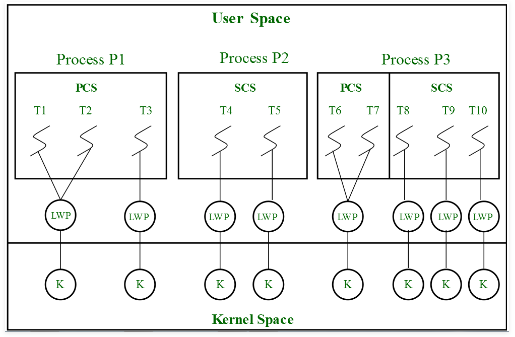
Multi-Process Scheduling
The term Multiprocessor now applies to the following system architectures:
- Multicore CPUs
- Multithreaded cores
- NUMA systems
Symmetric multiprocessing (SMP)
Symmetric multiprocessing (SMP) is where each processor is self scheduling
- All threads may be in a common ready queue (a)
所有进程共用一个就绪队列 - Each processor may have its own private queue of threads(b)
每个处理机都有私有的队列
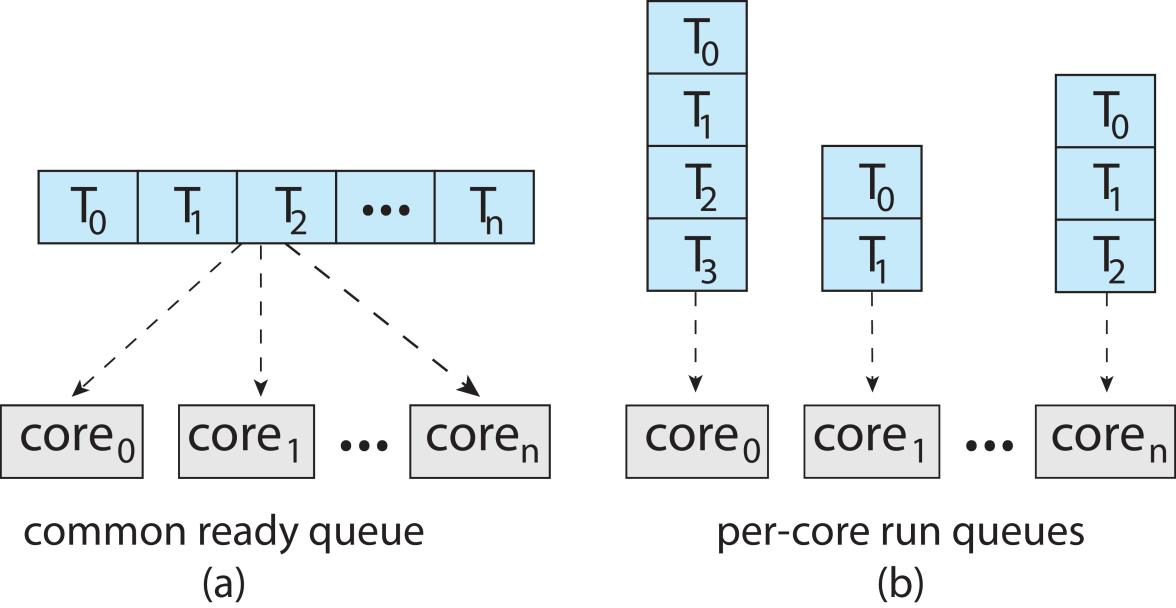
Multicore Processors
When multiple processor cores are on same physical chip ----》 Multicore Processor
- Multicore Processor ==> Recent trend
Faster and consumes less power
Memory Stall Growing[3]
Solution: 每个核都有多个硬件线程
- Each core has more than one hardware threads. If one thread has a memory stall, switch to another thread!
Multithreaded Multicore System
Chip-multithreading CMT assigns each core multiple hardware threads.
- (Intel refers to this as hyper-threading.)
On a quad-core system (4核) with 2 hardware threads per core, the operating system sees 8 logical processors.
在一个四核(4核)系统中,如果每个核心支持2个硬件线程,操作系统看到的8个逻辑处理器其实是由这种硬件线程技术(也称为超线程技术)使得每个物理核心能够同时处理两个线程。这种技术允许CPU更高效地利用其资源,特别是在某些核心的一部分资源(如执行单元)在特定时刻未被充分使用时。
具体来说,超线程技术通过使每个物理核心在操作系统层面呈现为两个逻辑处理器来工作。这样,操作系统和应用程序可以将这些逻辑处理器视为独立的处理单元,从而在逻辑上扩展了CPU的并行处理能力。
因此,在这样一个四核处理器中,由于每个核心可以处理两个线程,总共就有(4 \times 2 = 8)个逻辑处理器。这就是操作系统为什么会看到8个逻辑处理器的原因。这种安排使得处理器在处理多任务或多线程应用程序时更为高效,尤其是在等待I/O操作或进行其他非CPU密集型任务时,可以更好地利用CPU资源。
Two levels of scheduling: 可以在两个层次调度 Multithreaded Multicore System
- The operating system deciding which software thread to run on a logical CPU
OS决定谁进CPU(逻辑上) - Each core decides which hardware thread to run on the physical core
Core 决定谁进入物理核心
Multiple-Processor Scheduling - Loading Balancing ----负载均衡
Load balancing attempts to keep workload evenly distributed
- Push migration – periodic task checks load on each processor, and pushes tasks from overloaded CPU to other less loaded CPUs
- Pull migration – idle CPUs pulls waiting tasks from busy CPU
Push and pull migration need not be mutually exclusive 推迁移、拉迁移不必相互互斥
- They are often implemented in parallel on load-balancing systems.
Multiple-Processor Scheduling – Processor Affinity 处理器亲和力
处理器亲和性指的是线程或进程倾向于在被分配运行的同一个CPU上运行的性质。 当线程在一个处理器上运行时,它的数据会被存储在该处理器的高速缓存(cache)中。如果这个线程之后继续在同一个处理器上运行,它可以更快地访问之前的数据,因为数据已经在缓存中了。
Load balancing may affect processor affinity
-
A thread may be moved from one processor to another to balance loads
-
That thread loses the contents of what it had in the cache of the processor it was moved off
-
Soft affinity
软亲和性:操作系统会尽量让线程在同一个处理器上运行,但不保证。系统负载均衡器可能会根据需要将线程迁移到其他处理器。
-
Hard affinity
应亲和性:进程可以指定它希望运行的处理器集合。如果设置了硬亲和性,即使在负载高的情况下,内核也不会将进程移动到它未指定运行的处理器上。
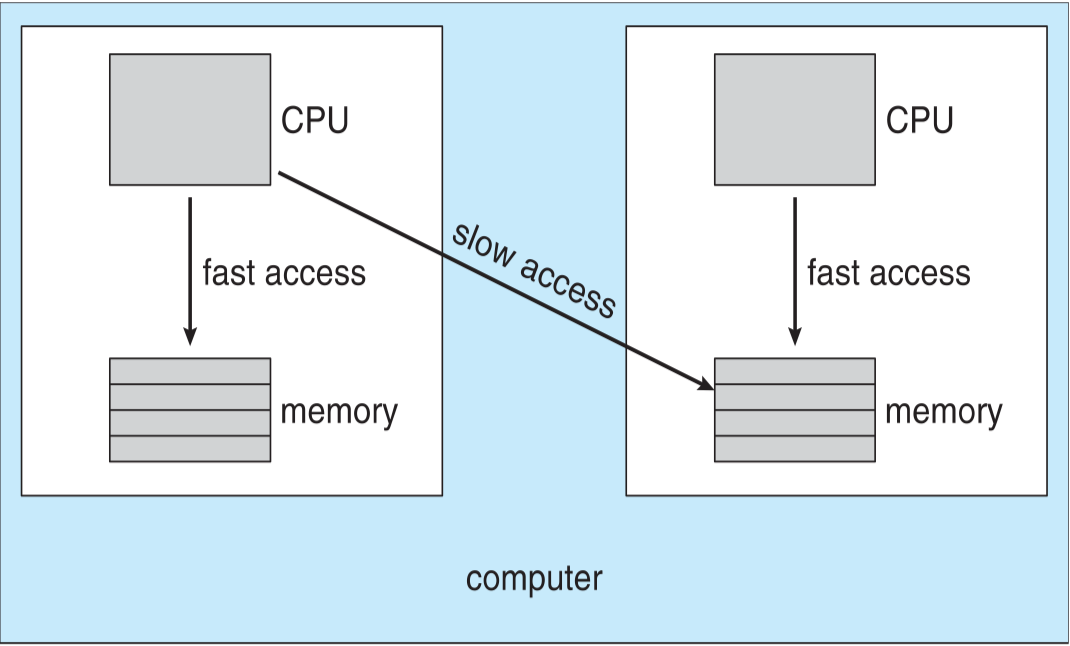
NUMA and CPU Scheduling
在NUMA架构中,计算机的内存被分割成多个区域,每个CPU都有一块局部内存。这些内存区域之间的访问速度可能不一样:
局部内存(Local memory):与某个CPU相邻的内存,这个CPU访问局部内存的速度快(fast access)。
非局部内存(Non-local memory):不与该CPU相邻的内存,该CPU访问非局部内存的速度慢(slow access)。
NUMA-aware操作系统在调度线程到CPU时会考虑内存访问的非一致性。它会尝试将线程分配到可以快速访问所需数据的CPU上。这意味着操作系统会考虑线程正在使用的数据的内存位置,并尽量让线程在靠近这些数据的CPU上运行。
这样做的好处是减少了内存访问延迟,提高了处理速度。但是,如果线程被调度到远离其数据的CPU上,它访问内存的速度将会慢下来,这可能会降低性能。
Real-Time CPU Scheduling
实时CPU调度(Real-Time CPU Scheduling)是一种操作系统的调度机制,它确保能够满足实时任务的时间要求。实时操作系统(RTOS)通常需要这种调度策略,因为它们运行着要求在特定时间内完成或响应的任务。
- Soft real-time systems
尽可能在截止时间内完成任务- Critical real-time tasks have the highest priority, but no guarantee as to when tasks will be scheduled (best try only)
- Hard real-time systems
严格在截止时间前完成任务- a task must be serviced by its deadline (guarantee)
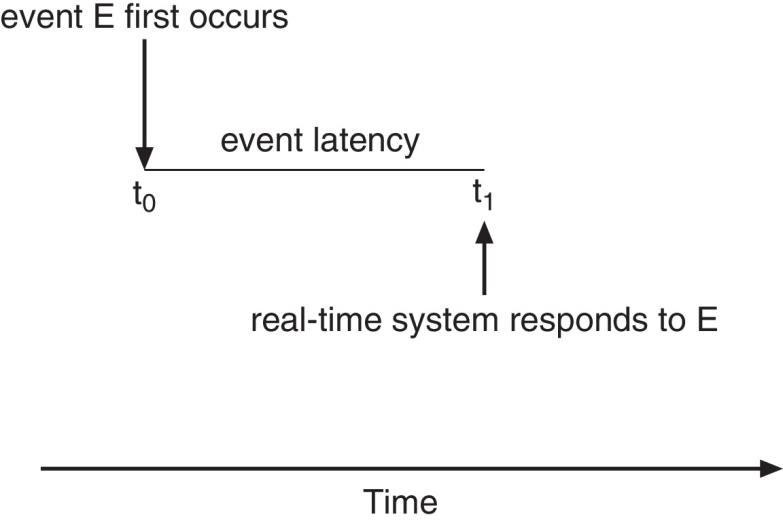
Event Latency 事件延迟
- the amount of time that elapses from when an event occurs to when it is serviced.
- Interrupt latency
中断延迟– time from arrival of interrupt to start of kernel interrupt service routine (ISR) that services interrupt - Dispatch latency
调度延迟– time for scheduler to take current process off CPU and switch to another
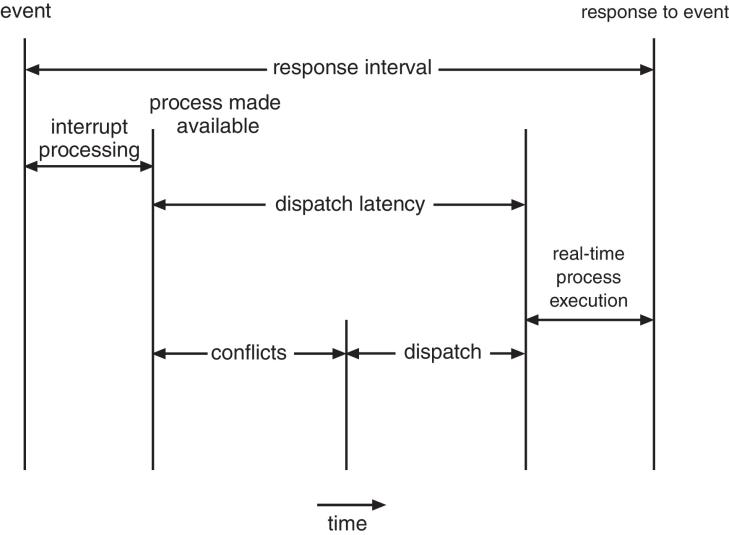
Priority-based Scheduling
- But only guarantees soft real-time
- For hard real-time, must also provide ability to meet deadlines
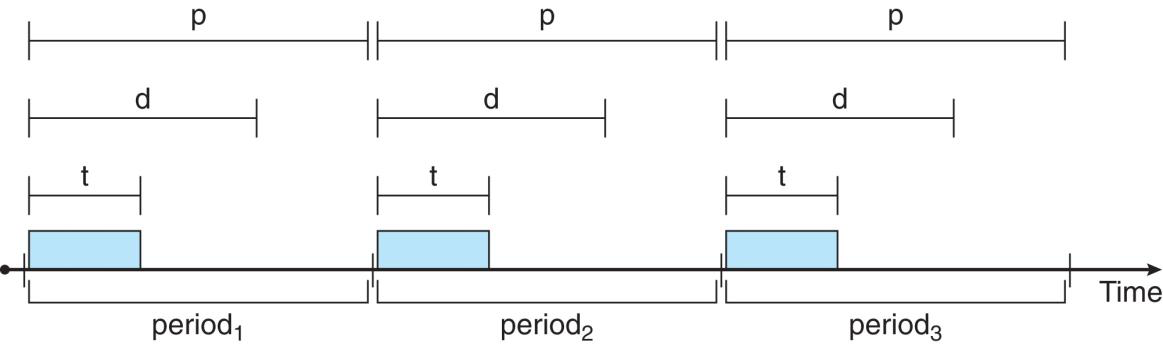
Rate Monotonic Scheduling
Priority is assigned based on the inverse of its period
Asume Priority :
-
-
Assume deadline
假定每个任务的截止时间d等于其周期p,即每个任务必须在下一个周期开始之前完成。

-
-

- In this case It can't satisfy the
Hard real-time systems
Earliest Deadline First Scheduling EDF
Priorities are assigned according to deadlines
-
-

Proportional Share Scheduling
T shares are allocated among all processes in the system
T = 20, therefore there are 20 shares, where one share represents 5% of the CPU time
- An application receives N shares where
- This ensures each application will receive
- Example: an application receives N = 5 shares the application then has 5 / 20 = 25% of the CPU time.
- This percentage of CPU time is available to the application whether the application uses it or not.
- 无论应用程序是否使用这些CPU时间,这些份额都被保留给它。
Operating System Examples
- Linux Scheduling
- Windows Scheduling
Linux Scheduling
- 2 scheduling classes are included, others can be added
- default
- real-time
- Each process/task has specific priority
- Real-time scheduling according to POSIX.1b
- Real-time tasks have static priorities
- Real-time plus normal tasks map into global priority scheme
- Nice value of -20 maps to global priority 100
- Nice value of +19 maps to priority 139
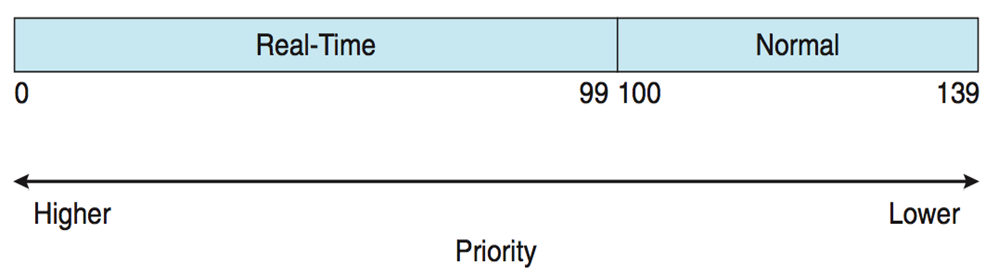
Completely Fair Scheduler CFS
Scheduler picks highest priority task in highest scheduling class
- Quantum is not fixed
时间片不固定 - Calculated based on nice value from -20 to +19
- Lower value is higher priority
- CFS maintains per task virtual run time in variable
vruntime[8] - Associated with decay factor based on priority of task => lower priority is higher decay rate [9]
- Normal default priority (Nice value: 0) yields virtual run time = actual run time
- To decide next task to run, scheduler picks task with lowest virtual run time [10]

Windows Scheduling
Windows uses priority-based preemptive scheduling
-
Highest-priority thread runs next
- Thread runs until
-
- blocks,
-
- uses time slice,
-
- preempted by higher-priority thread
-
- Thread runs until
-
Real-time threads can preempt non-real-time
-
32-level priority scheme
- Variable class is 1-15, real-time class is 16-31
- Priority 0 is memory-management thread
- There is a queue for each priority
- If no run-able thread, runs idle thread
-
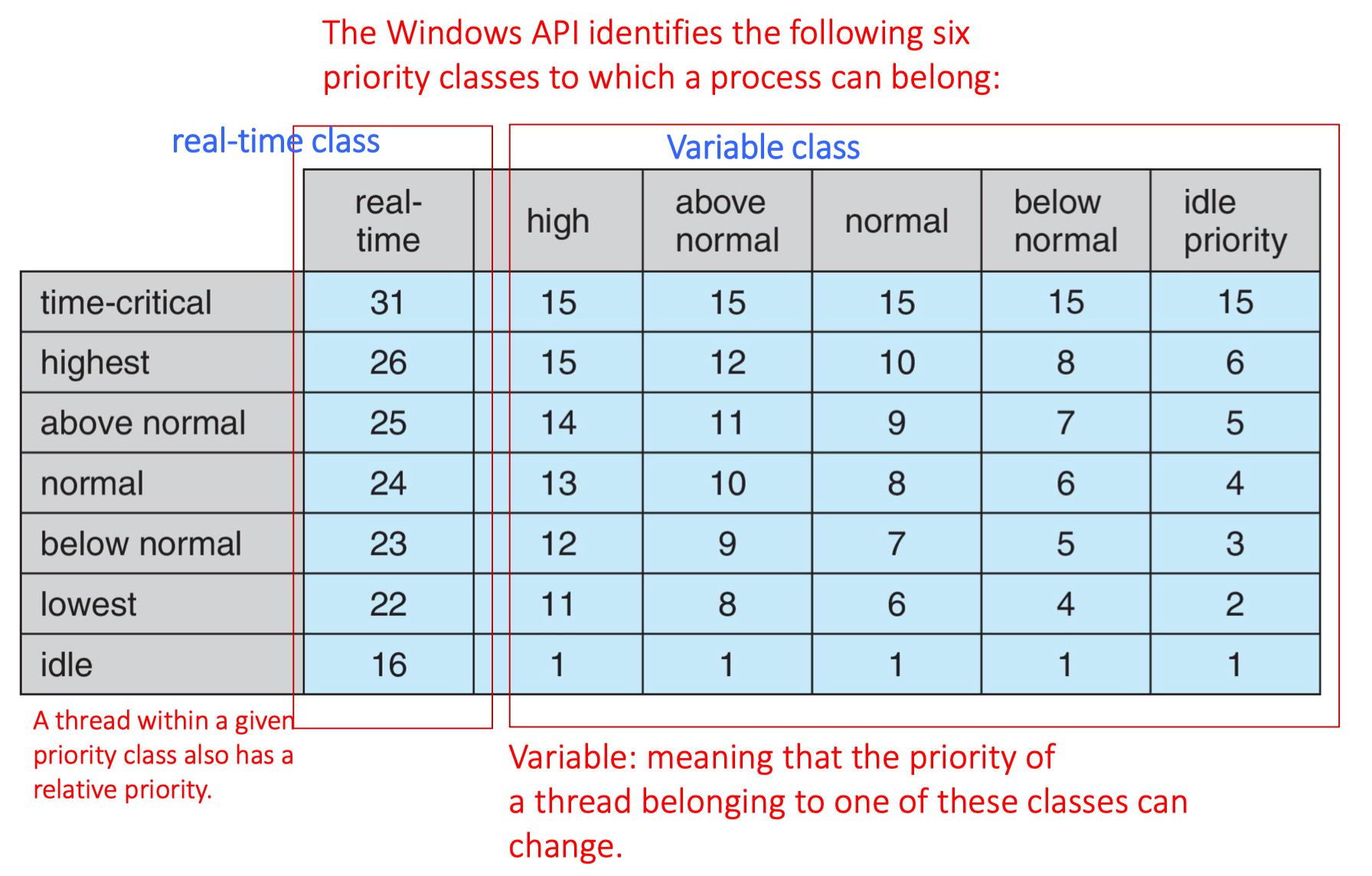
-
Windows操作系统中进程可以属于六种优先级类别,每个类别中各个相对优先级的数值。Windows API定义了实时类(real-time class)和变量类(variable class),每个类别中都有不同的优先级级别。
-
在实时类别中,有一个时间关键(time-critical)优先级,这是最高的优先级,数值为31。其他优先级依次降低,直到最低的空闲(idle)优先级,数值为16。这些优先级是为需要即时响应的任务设计的,比如那些在特定时间限制内必须完成的任务。
-
在变量类别中,优先级从高(high)到空闲(idle)不等。每个优先级类别还有相对优先级,如正常(normal)类别的优先级数值范围从15到6不等。这些优先级通常用于普通应用程序和后台任务。
-
“变量”(Variable 意味着线程的优先级可以改变,即使它们属于同一类别。这允许操作系统根据当前的需求和资源情况动态调整进程的优先级。
-
在调度时,系统会选择优先级数值最高的线程来执行,确保时间敏感的任务能够获得及时的处理。通过这种方式,操作系统可以管理多任务环境中的资源分配,确保关键任务能够及时完成,同时为不太重要的任务提供必要的CPU时间。
- keep the CPU as busy as possible↩︎
- Increase throughput as high as possible↩︎
- An event that occurs when a thread is on CPU and accesses memory content that is not in the CPU’s cache. The thread’s execution stalls while the memory content is retrieved and fetched↩︎
- 处理时间↩︎
- 截止时间↩︎
- 周期时间↩︎
- 周期任务的频率↩︎
- 虚拟运行时间(vruntime):CFS使用一个名为
vruntime的变量来追踪每个进程应该获得的CPU时间。vruntime的增加速度取决于进程的优先级:优先级较低的进程(nice值较高)的vruntime增长得更快。↩︎ - 衰减因子:CFS使用衰减因子来根据进程的优先级调整其
vruntime,优先级越低的进程,其vruntime的增长越快,从而减少它们被调度的概率。↩︎ - 选择下一个运行的进程:当需要选择下一个运行的进程时,CFS选择
vruntime最低的进程,以尝试平等地分配CPU时间给每个进程。↩︎
{kind=link}